使用Prometheus Operator监控kubetnetes集群
閱讀本文約花費: 9 (分鐘)
一、简介
Prometheus
Prometheus 是一个开源监控系统,它本身已经成为了云原生中指标监控的事实标准,几乎所有 Kubernetes 的核心组件以及其它云原生系统都以 Prometheus 的指标格式输出自己的运行时监控信息。
主要特性:
- 使用指标名称及键值对标识的多维度数据模型。
- 采用弹性查询语言PromQL。
- 不依赖分布式存储,为自治的单点服务。
- 使用http完成对监控数据的拉取。
- 通过网关支持时序数据的推送。
- 支持多种图形和Dashboard的展示。
另外在Prometheus的整个生态系统中有各种可选组件,用于功能的扩充。
Prometheus-Operator
CoreOS提供了一种名为Operator的管理工具,他是管理特定应用程序的控制器。通过扩展Kubernetes API以软件的方式帮助用户创建、配置和管理复杂的或又状态的应用程序实例(如etcd、Redis、MySQL、Prometheus等)。
它通过Kubernetes的CRD(Custom Resource Definition,自定义资源定义)对Prometheus和Prometheus需要监控的服务进行部署和配置。
Prometheus-Operator使用下面两种资源来配置Prometheus及其要监控的服务。
- Prometheus:为Prometheus的deployment。
- ServiceMonitor:用于描述Prometheus监控的服务。
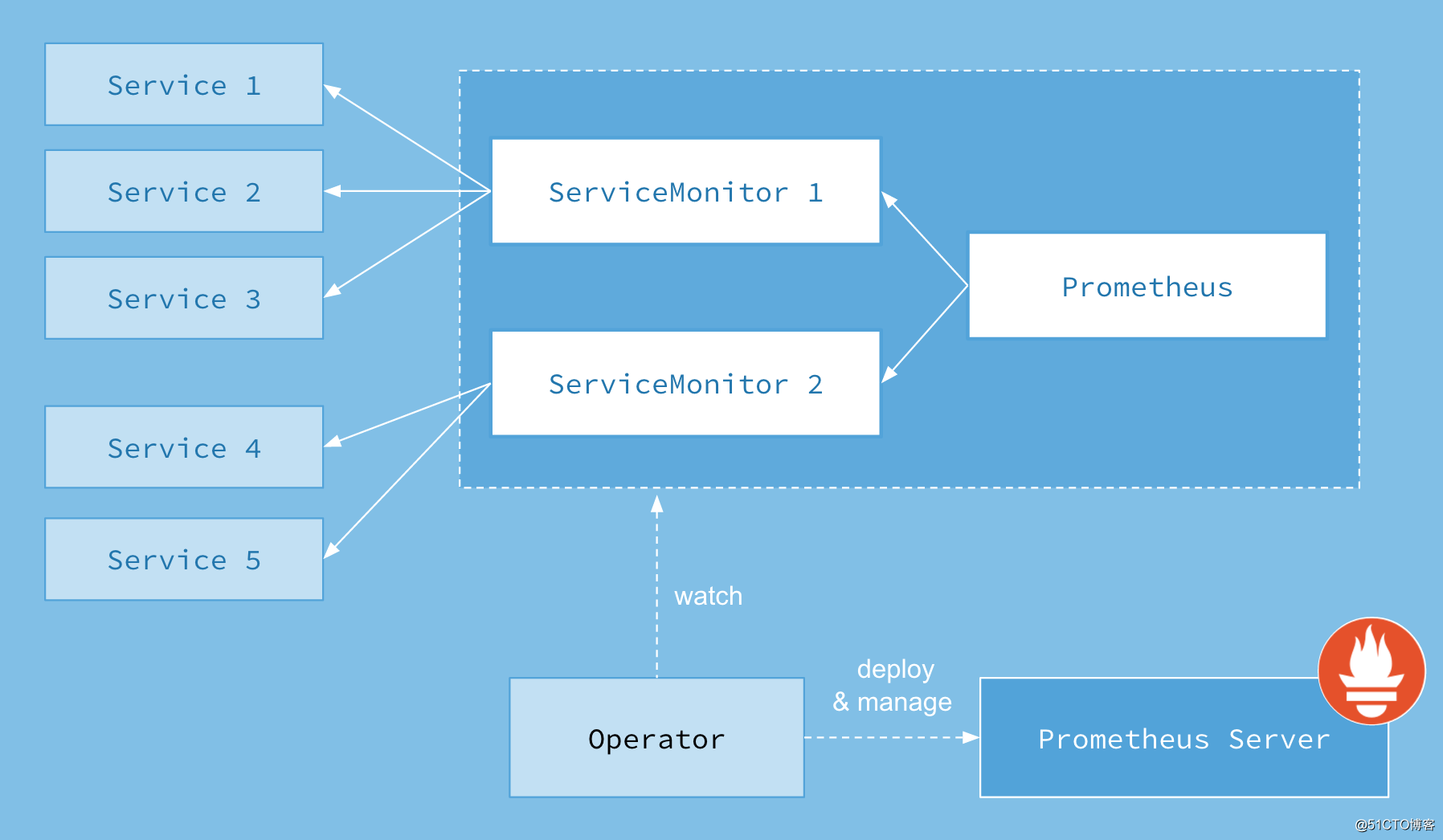
首先我们先来了解下 Prometheus-Operator 的架构图:
上图是 Prometheus-Operator 官方提供的架构图,其中 Operator 是最核心的部分,作为一个控制器,他会去创建 Prometheus 、 ServiceMonitor 、 AlertManager 以及 PrometheusRule 4个 CRD 资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的 prometheus 这种资源对象就是作为 Prometheus Server 存在,而 ServiceMonitor 就是 exporter 的各种抽象, exporter是用来提供专门提供 metrics 数据接口的工具, Prometheus 就是通过 ServiceMonitor 提供的 metrics 数据接口去 pull 数据的。
当然 alertmanager 这种资源对象就是对应的 AlertManager 的抽象,而 PrometheusRule 是用来被 Prometheus 实例使用的报警规则文件。
二、说明
- 本文档基于Prometheus Operator对Prometheus监控系统而进行,完整的配置文件请参考https://github.com/coreos/prometheus-operator
- 本文使用的k8s集群是基于kubeadm搭建的,具体搭建的详细请参考https://blog.51cto.com/billy98/2350660
三、部署
1. 环境准备
配置Prometheus-Operator之前需要先准备以下几个环境:
- Helm环境:请参考https://blog.51cto.com/billy98/2338415
- gluster-heketi环境:因为prometheus和alertmanager都是有状态的statefulsets集群,所以需要使用到公共存储。请参考https://blog.51cto.com/billy98/2337874
- Ingress环境:请参考https://blog.51cto.com/billy98/2337874
2. 配置域名解析
将alert.cnlinux.club、grafana.cnlinux.club、prom.cnlinux.club三个域名的A记录解析到负责均衡的IP10.31.90.200。
3. 修改scheduler、controller-manager监听地址
修改/etc/kubernetes/manifests/ 目录下kube-controller-manager.yaml和kube-scheduler.yaml
将监听地址改成--address=0.0.0.0,重启kubelet服务
systemctl restart kubelet.service
4. 创建Namespace
kubectl create ns monitoring
5. 创建Secret
因为etcd是使用https访问的,所以prometheus的容器中也必须要etcd的证书去监控etcd集群,创建Secret就是将证书挂载到prometheus容器中,后续还需要在Prometheus-Operator的配置文件中使用此Secret。
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-clien t.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt
6. 配置Prometheus-Operator
1)首先使用helm下载Prometheus-Operator文件包。
helm fetch stable/prometheus-operator
2)解压下载的压缩包
tar zxf prometheus-operator-1.8.0.tgz
并修改prometheus-operator目录下的values.yaml。
具体修改的配置如下(配置过多,其他未修改的就不再展示了):
nameOverride: "p"
alertmanager:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
labels: {}
hosts:
- alert.cnlinux.club
tls: []
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: gluster-heketi
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
selector: {}
grafana:
enabled: true
adminPassword: admin
#grafana登录密码
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
labels: {}
hosts:
- grafana.cnlinux.club
kubeApiServer:
enabled: true
tlsConfig:
serverName: kubernetes
insecureSkipVerify: true
serviceMonitor:
jobLabel: component
selector:
matchLabels:
component: apiserver
provider: kubernetes
kubelet:
enabled: true
namespace: kube-system
serviceMonitor:
https: true
kubeControllerManager:
enabled: true
endpoints: []
service:
port: 10252
targetPort: 10252
selector:
component: kube-controller-manager
coreDns:
enabled: true
service:
port: 9153
targetPort: 9153
selector:
k8s-app: kube-dns
kubeEtcd:
enabled: true
endpoints: []
service:
port: 2379
targetPort: 2379
selector:
component: etcd
serviceMonitor:
scheme: https
insecureSkipVerify: false
serverName: ""
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key
#secret etcd-certs挂载在prometheus的路径是/etc/prometheus/secrets/etcd-certs,证书文件名和secret一样
kubeScheduler:
enabled: true
endpoints: []
service:
port: 10251
targetPort: 10251
selector:
component: kube-scheduler
prometheus:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
labels: {}
hosts:
- prom.cnlinux.club
prometheusSpec:
secrets: [etcd-certs]
#上面步骤创建etcd证书的secret
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gluster-heketi
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
selector: {}
3) 安装prometheus-operator
[root@node-01 ~]# helm install --name p --namespace monitoring ./prometheus-operator NAME: p LAST DEPLOYED: Tue Feb 26 14:30:52 2019 NAMESPACE: monitoring STATUS: DEPLOYED RESOURCES: ==> v1beta1/DaemonSet NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE p-prometheus-node-exporter 6 6 1 6 1 <none> 5s ==> v1beta2/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE p-grafana 1 1 1 0 5s ==> v1/PrometheusRule NAME AGE p-alertmanager.rules 4s p-etcd 4s p-general.rules 4s p-k8s.rules 4s p-kube-apiserver.rules 4s p-kube-prometheus-node-alerting.rules 4s p-kube-prometheus-node-recording.rules 4s p-kube-scheduler.rules 4s p-kubernetes-absent 4s p-kubernetes-apps 4s p-kubernetes-resources 4s p-kubernetes-storage 4s p-kubernetes-system 4s p-node.rules 4s p-prometheus-operator 4s p-prometheus.rules 4s ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE p-prometheus-node-exporter-48lw9 0/1 Running 0 5s p-prometheus-node-exporter-7lpvx 0/1 Running 0 5s p-prometheus-node-exporter-8q577 1/1 Running 0 5s p-prometheus-node-exporter-ls8cx 0/1 Running 0 5s p-prometheus-node-exporter-nbl2g 0/1 Running 0 5s p-prometheus-node-exporter-v7tb5 0/1 Running 0 5s p-grafana-fcf4dc6bb-9c6pg 0/3 ContainerCreating 0 5s p-kube-state-metrics-57d788d69-vmh42 0/1 Running 0 5s p-operator-666b958c4f-wvd4h 1/1 Running 0 5s ==> v1beta1/ClusterRole NAME AGE p-kube-state-metrics 6s psp-p-prometheus-node-exporter 6s ==> v1/Service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE p-grafana ClusterIP 10.245.103.159 <none> 80/TCP 5s p-kube-state-metrics ClusterIP 10.245.150.181 <none> 8080/TCP 5s p-prometheus-node-exporter ClusterIP 10.245.98.70 <none> 9100/TCP 5s p-alertmanager ClusterIP 10.245.10.5 <none> 9093/TCP 5s p-coredns ClusterIP None <none> 9153/TCP 5s p-kube-controller-manager ClusterIP None <none> 10252/TCP 5s p-kube-etcd ClusterIP None <none> 2379/TCP 5s p-kube-scheduler ClusterIP None <none> 10251/TCP 5s p-operator ClusterIP 10.245.31.238 <none> 8080/TCP 5s p-prometheus ClusterIP 10.245.109.85 <none> 9090/TCP 5s ==> v1/ClusterRoleBinding NAME AGE p-grafana-clusterrolebinding 6s p-alertmanager 6s p-operator 6s p-operator-psp 6s p-prometheus 6s p-prometheus-psp 6s ==> v1beta1/ClusterRoleBinding NAME AGE p-kube-state-metrics 6s psp-p-prometheus-node-exporter 6s ==> v1beta1/Role NAME AGE p-grafana 6s ==> v1/RoleBinding NAME AGE p-prometheus-config 5s p-prometheus 4s p-prometheus 4s ==> v1/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE p-operator 1 1 1 1 5s ==> v1/Alertmanager NAME AGE p-alertmanager 5s ==> v1/Secret NAME TYPE DATA AGE p-grafana Opaque 3 6s alertmanager-p-alertmanager Opaque 1 6s ==> v1/ServiceAccount NAME SECRETS AGE p-grafana 1 6s p-kube-state-metrics 1 6s p-prometheus-node-exporter 1 6s p-alertmanager 1 6s p-operator 1 6s p-prometheus 1 6s ==> v1beta1/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE p-kube-state-metrics 1 1 1 0 5s ==> v1beta1/Ingress NAME HOSTS ADDRESS PORTS AGE p-grafana grafana.cnlinux.club 80 5s p-alertmanager alert.cnlinux.club 80 5s p-prometheus prom.cnlinux.club 80 5s ==> v1beta1/PodSecurityPolicy NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES p-grafana false RunAsAny RunAsAny RunAsAny RunAsAny false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim p-prometheus-node-exporter false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim,hostPath p-alertmanager false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim p-operator false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim p-prometheus false RunAsAny RunAsAny MustRunAs MustRunAs false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim ==> v1/ConfigMap NAME DATA AGE p-grafana-config-dashboards 1 6s p-grafana 1 6s p-grafana-datasource 1 6s p-etcd 1 6s p-grafana-coredns-k8s 1 6s p-k8s-cluster-rsrc-use 1 6s p-k8s-node-rsrc-use 1 6s p-k8s-resources-cluster 1 6s p-k8s-resources-namespace 1 6s p-k8s-resources-pod 1 6s p-nodes 1 6s p-persistentvolumesusage 1 6s p-pods 1 6s p-statefulset 1 6s ==> v1beta1/RoleBinding NAME AGE p-grafana 5s ==> v1/Prometheus NAME AGE p-prometheus 4s ==> v1/ServiceMonitor NAME AGE p-alertmanager 4s p-coredns 4s p-apiserver 4s p-kube-controller-manager 4s p-kube-etcd 4s p-kube-scheduler 4s p-kube-state-metrics 4s p-kubelet 4s p-node-exporter 4s p-operator 4s p-prometheus 4s ==> v1/ClusterRole NAME AGE p-grafana-clusterrole 6s p-alertmanager 6s p-operator 6s p-operator-psp 6s p-prometheus 6s p-prometheus-psp 6s ==> v1/Role NAME AGE p-prometheus-config 6s p-prometheus 4s p-prometheus 4s NOTES: The Prometheus Operator has been installed. Check its status by running: kubectl --namespace monitoring get pods -l "release=p" Visit https://github.com/coreos/prometheus-operator for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
6. 部署中遇到的问题
在部署中有几个坑,我在此列举一下,大家配置的时候需要注意一下
1)名称过长导致pvc创建失败
由于alertmanager和prometheus都是有状态的statefulsets,所以我们使用了gluster的存储,并通过 prometheus-operator自动创建pvc,如果charts的release 名称过长会导致pvc创建失败。
所以在上面的安装中指定了release的名字为phelm install --name p --namespace monitoring ./prometheus-operator,并且在配置文件中也修改了namenameOverride: "p"。
Warning ProvisioningFailed 3s (x2 over 40s) persistentvolume-controller Failed to provision volume with StorageClass "gluster-heketi": failed to create volume: failed to create endpoint/service default/glusterfs-dynamic-72488422-3428-11e9-a74b-005056824bdc: failed to create endpoint: Endpoints "glusterfs-dynamic-72488422-3428-11e9-a74b-005056824bdc" is invalid: metadata.labels: Invalid value: "alertmanager-prom-alertmanager-db-alertmanager-prom-alertmanager-0": must be no more than 63 characters
2)配置文件中labels
首先要查看pod的标签,然后修改修改prometheus-operator目录下的values.yaml对应的标签。
[root@node-01 ~]# kubectl -n kube-system get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS coredns-7f65654f74-6gxps 1/1 Running 8 5d22h k8s-app=kube-dns,pod-template-hash=7f65654f74 etcd-node-01 1/1 Running 1 32d component=etcd,tier=control-plane kube-controller-manager-node-01 1/1 Running 0 39h component=kube-controller-manager,tier=control-plane kube-scheduler-node-01 1/1 Running 0 23h component=kube-scheduler,tier=control-plane ...
需要注意的是一定要修改prometheus-operator目录下values.yaml对应的标签,不能在安装的时候指定外部的配置文件来覆盖labels值,这可能是个bug,指定外部配置时无法覆盖labels而是追加,会导致prometheus无法抓取到数据。
7. 更新和删除
如果在修改了配置文件values.yaml,可以使用以下命令更新prometheus-operator
helm upgrade RELEASE_NAME ./prometheus-operator
如果需要删除,可以使用以下命令
helm del --purge RELEASE_NAME kubectl -n monitoring delete crd prometheuses.monitoring.coreos.com kubectl -n monitoring delete crd prometheusrules.monitoring.coreos.com kubectl -n monitoring delete crd servicemonitors.monitoring.coreos.com kubectl -n monitoring delete crd alertmanagers.monitoring.coreos.com
8. 验证
部署完后可以在浏览器访问prometheushttp://prom.cnlinux.club/targets,可以看到如下图,所有的项都有数据,并且是UP状态的。
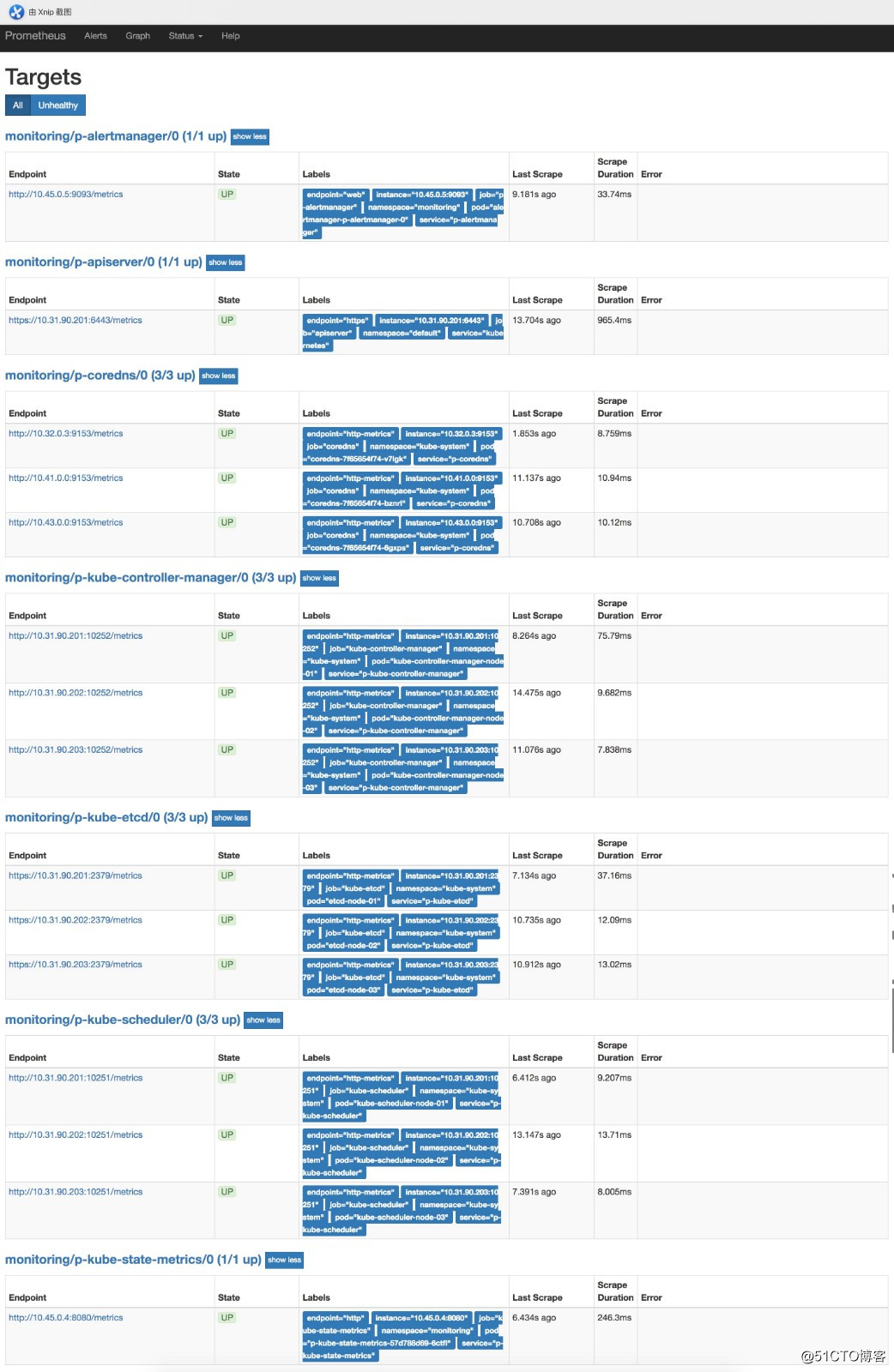
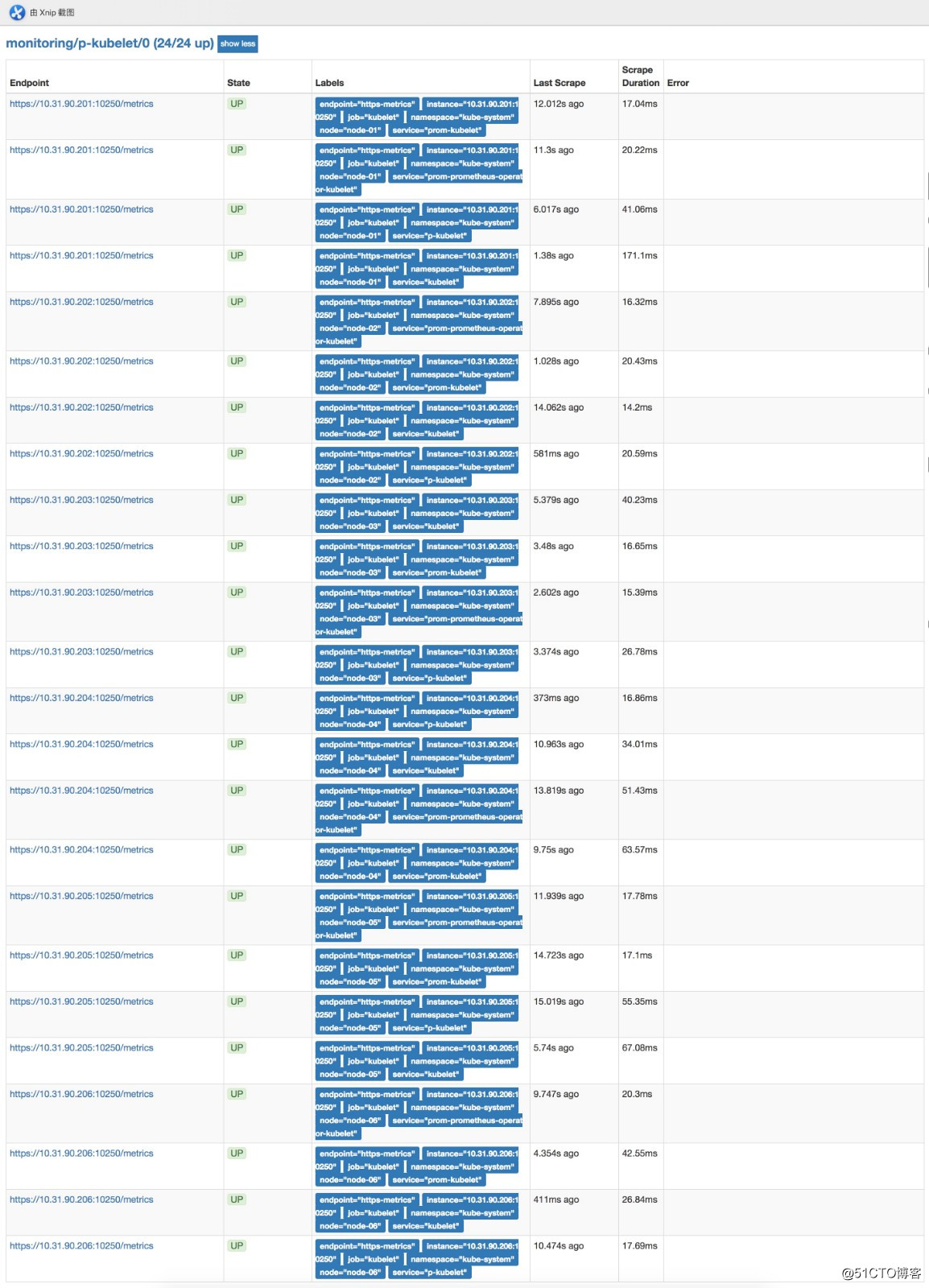
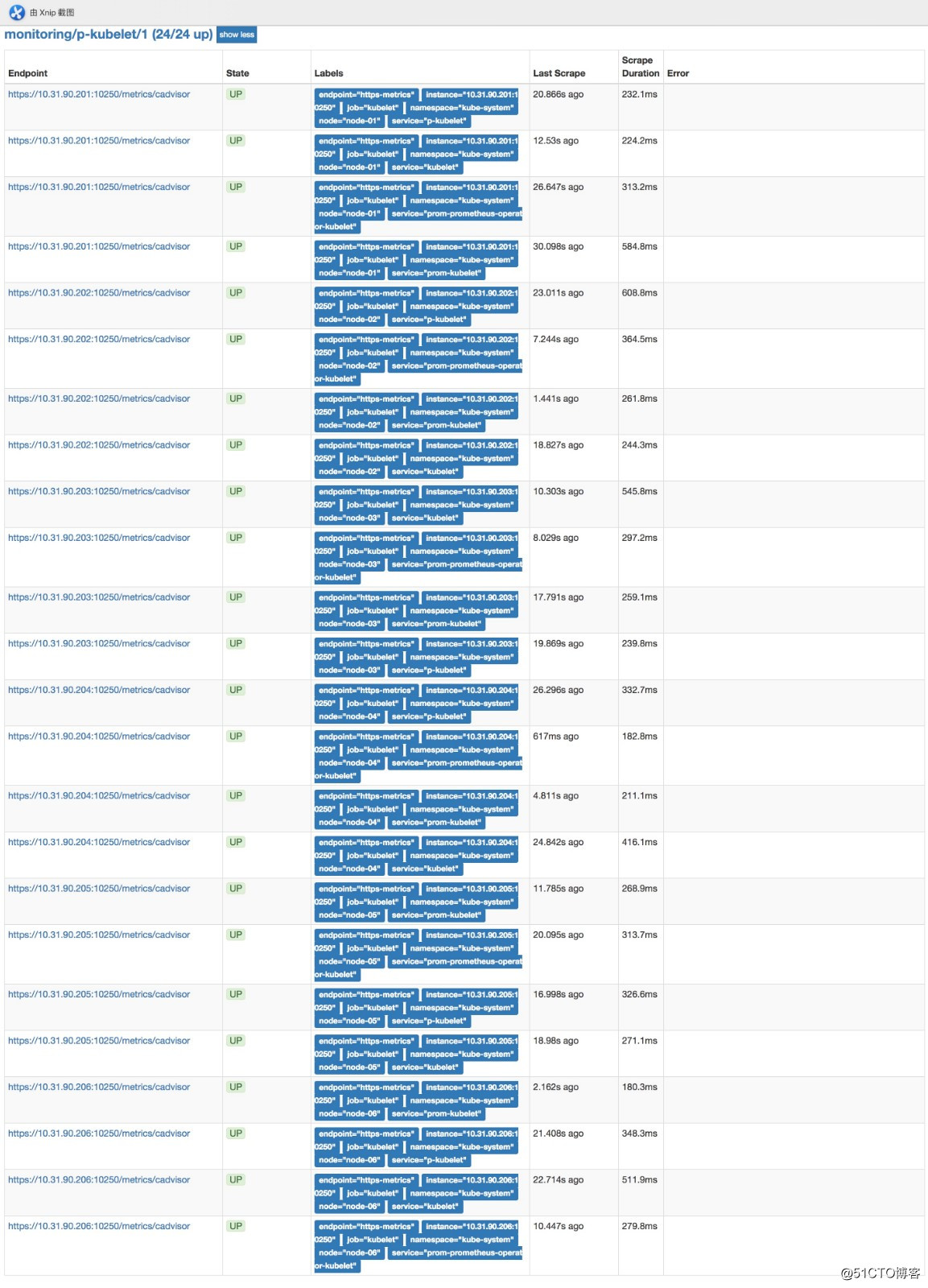
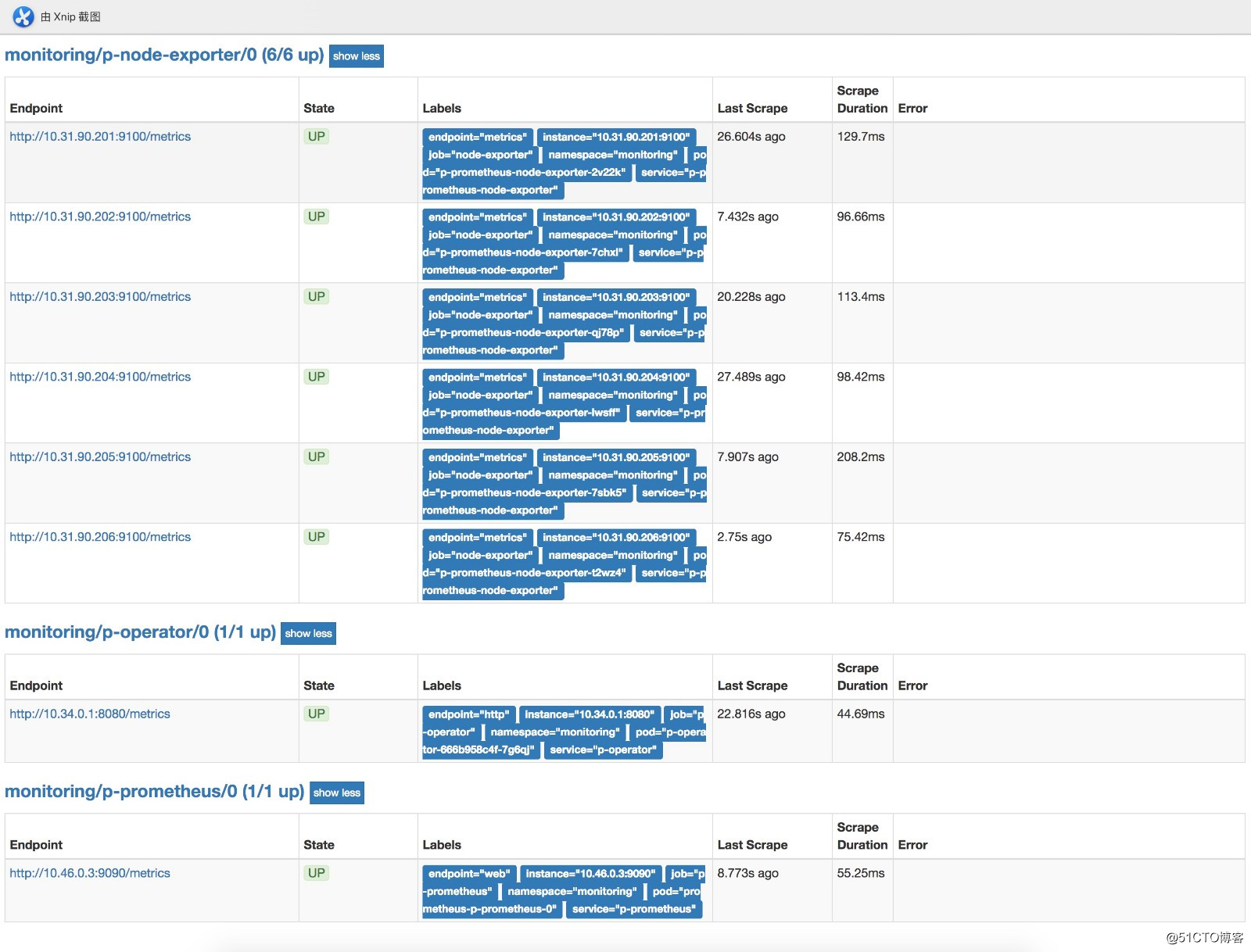
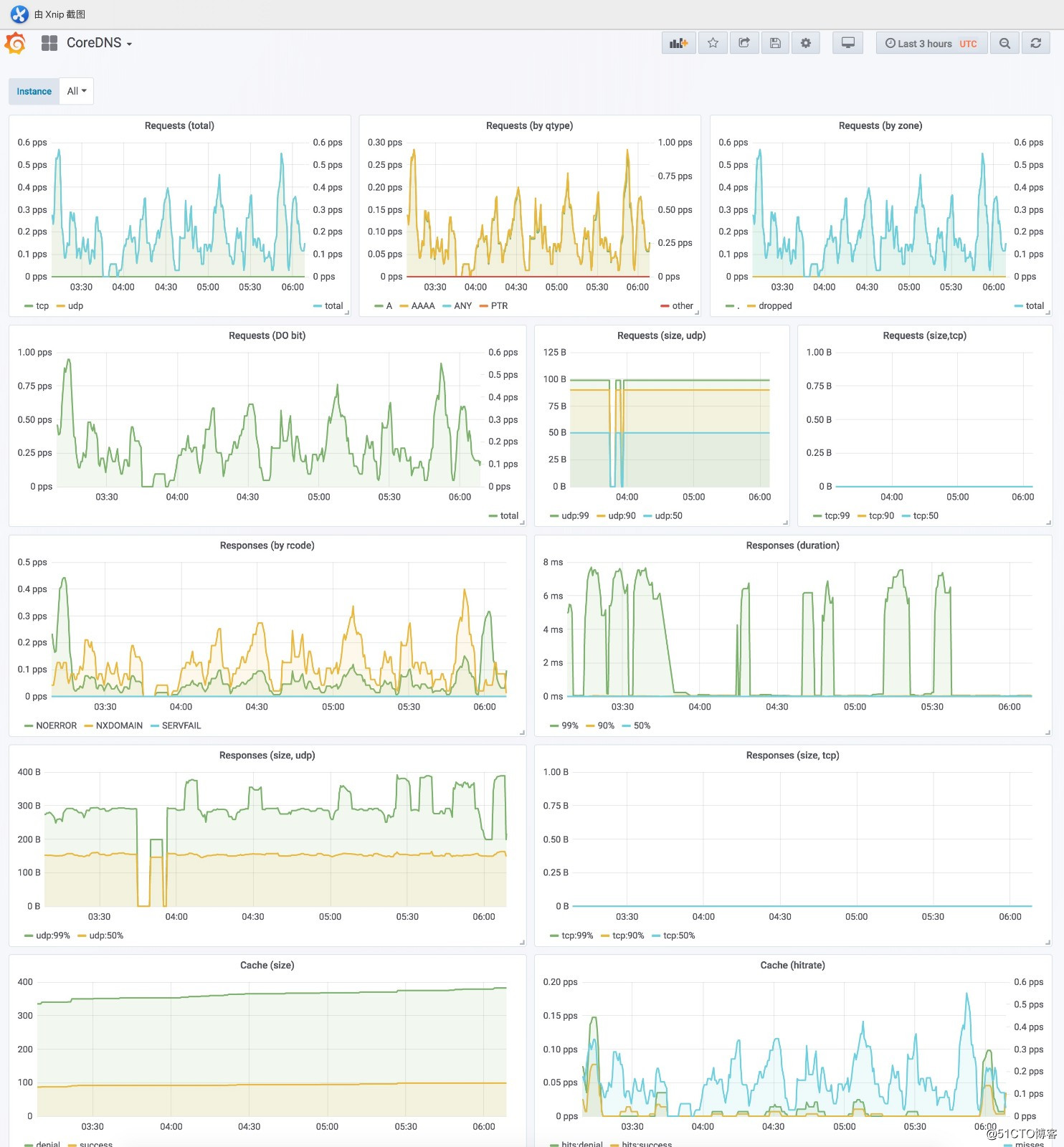
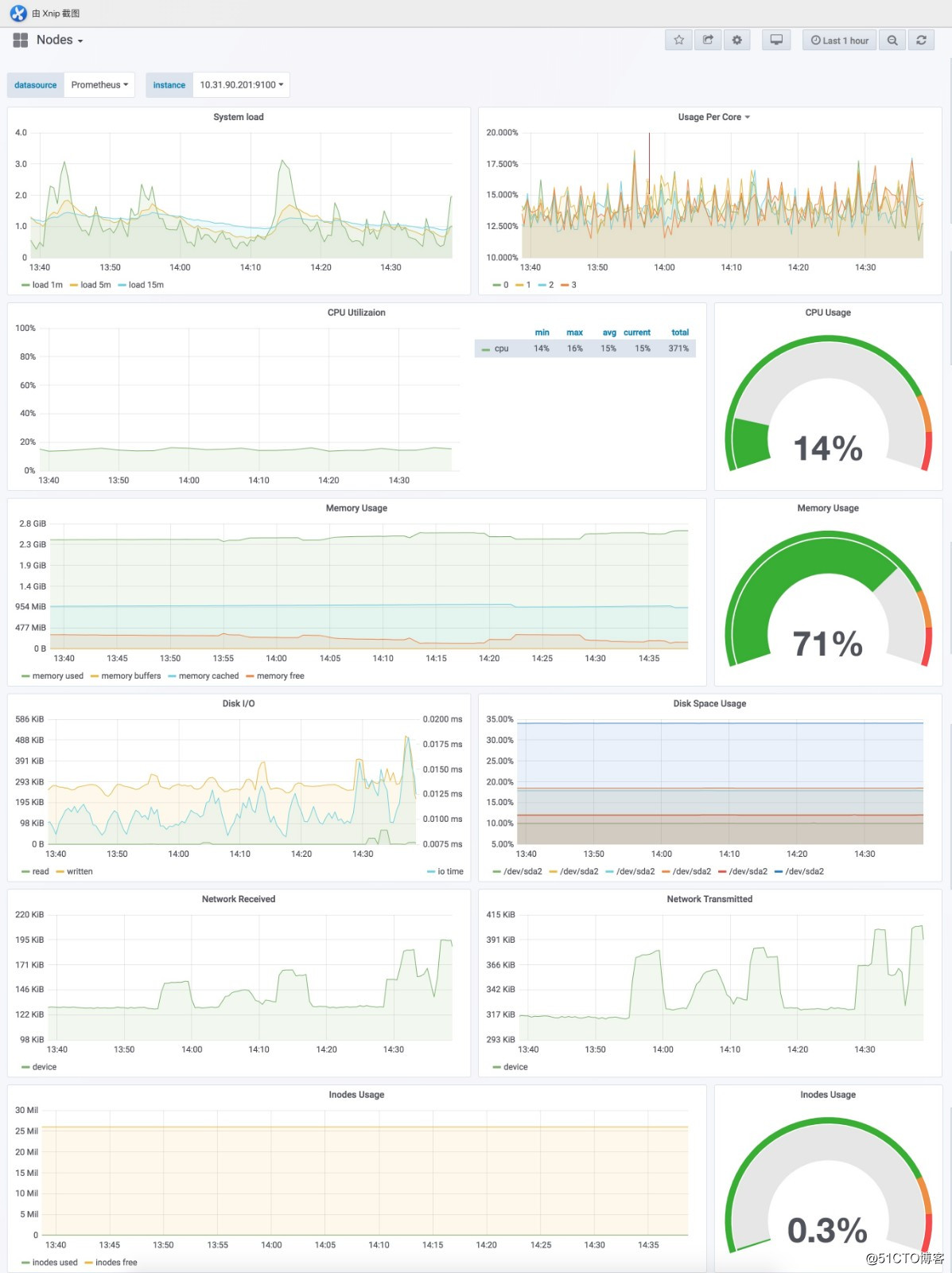
浏览器访问grafana http://grafana.cnlinux.club/,可以看到各种资源的监控图。
用户名为admin,密码为values.yaml配置文件中指定的密码
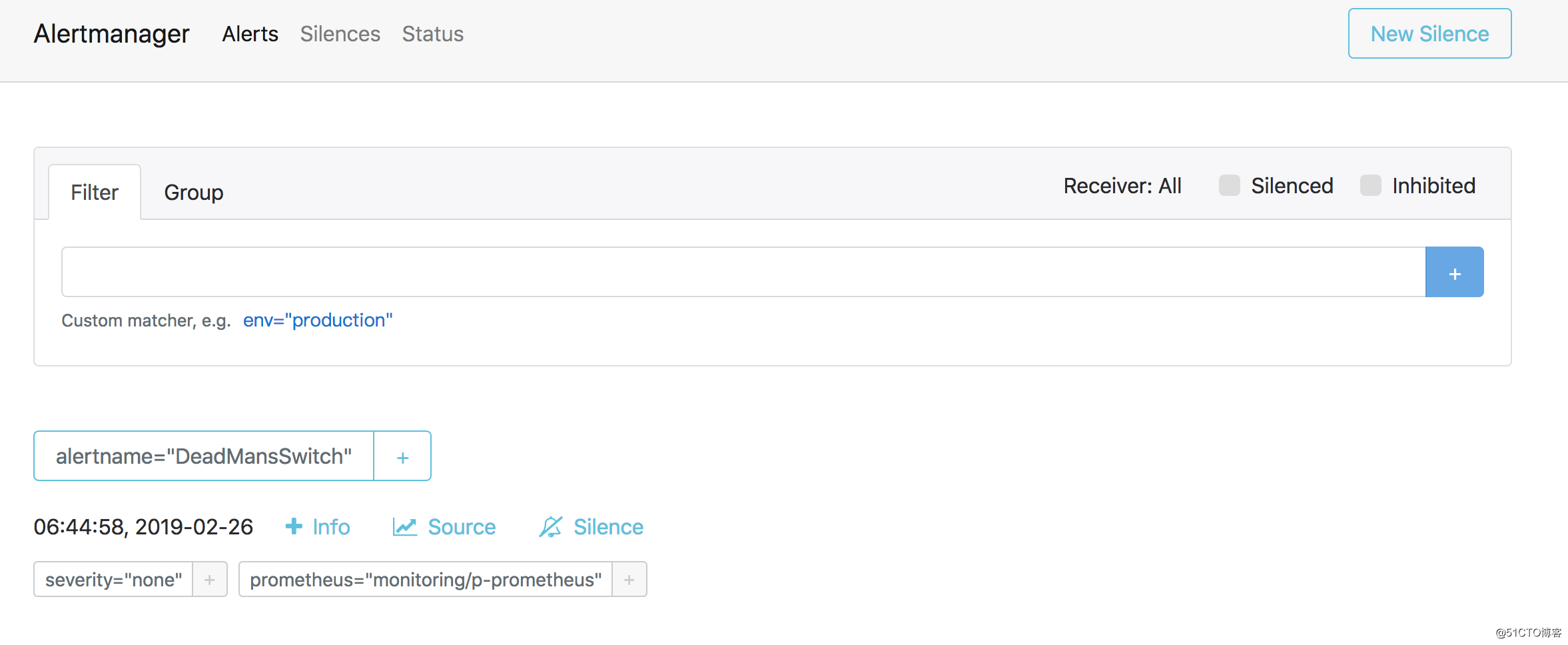
浏览器访问Alertmanagerhttp://alert.cnlinux.club/,可以看到报警项。
至此所有的安装完成,下一篇将详细说明使用prometheus监控自定义服务,以及报警设置。
3 thoughts on “使用Prometheus Operator监控kubetnetes集群”
Hi Dear, are you in fact visiting this web page on a regular basis,
if so after that you will absolutely obtain fastidious knowledge.
You really make it appear really easy together with your presentation however I in finding this matter
to be actually something that I believe I’d never understand.
It sort of feels too complicated and extremely wide for me.
I’m taking a look forward for your next post, I will try to
get the hold of it!
Hi friends, how is the whole thing, and what you want to say concerning this paragraph, in my view its really remarkable designed for me.|