Service Mesh Is Still Hard
閱讀本文約花費: 5 (分鐘)
KubeCon + CloudNativeCon NA Virtual sponsor guest post from Lin Sun, Senior Technical Staff Member at IBM
At ServiceMeshCon EU this August, William Morgan from Linkerd and I gave a joint talk entitled service mesh is still hard. William detailed the improvements to Linkerd, while I covered the improvements to Istio. It’s clear both projects are working hard to make it easier for users to adopt service mesh.
Service mesh is more mature than it was one or two years ago, however, it’s still hard for users. There are two types of technical roles for service mesh, platform owners and service owners. Platform owners, also called mesh admins, own the service platform and define the overall strategy and implementation for service owners to adopt service mesh. Service owners own one or more services in the mesh.
It’s become easier for platform owners to use service meshes because the projects are implementing ways to ease the configuration of the network, configuration of security policies, and visualization of the entire mesh. For example, within Istio, platform owners can set Istio authentication policies or authorization policies at whichever scope they prefer. Platform owners can configure the ingress gateway on hosts/ports/TLS related settings while delegating the actual routing behaviors and traffic policies of the destination service to service owners. Service owners implementing well tested and common scenarios are benefitting from usability improvement in Istio to easily onboard their microservices to the mesh. Service owners implementing less common scenarios continue to encounter a steep learning curve.
I believe service mesh is still hard for the following reasons:
1. Lack of clear guidance on whether you need service mesh
Before users start to evaluate multiple service meshes or dive into a particular service mesh, they need guidance on whether a service mesh could help. Unfortunately, this is not a simple yes/no question. There are multiple factors to consider:
- How many people are in your engineering organization?
- How many microservices do you have?
- What languages are being used for these microservices?
- Do you have experience adopting open source projects?
- What platforms are you running your services on?
- What features do you need from service mesh?
- Are the features stable for a given service mesh project?
Adding to the complexity, the answer may be different for the various service mesh projects. Even within Istio, we adopted microservices to fully leverage the mesh in earlier releases prior to Istio 1.5, but decided to turn multiple Istio control plane components into a monolithic application to reduce the operational complexity. For that instance, it made more sense to run one monolithic service instead of four or five microservices.
2. Your service may break immediately after a sidecar is injected
Last Thanksgiving, I was trying to help a user run a Zookeeper service in the mesh using the latest Zookeeper helm charts. Zookeeper runs as a Kubernetes StatefulSet. As soon as I tried to inject the envoy sidecar proxy into each Zookeeper pod, the Zookeeper pods would not run and kept restarting because they were unable to establish the leader and communication among the members. By default, Zookeeper listens on the pod IP address for communication between servers. However, Istio and other service meshes require localhost (127.0.0.1) to be the address to listen on which made the Zookeeper servers unable to communicate with each other.
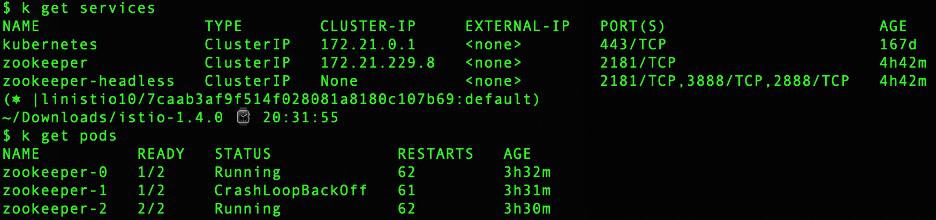
Working with the upstream community, we have added a configuration workaround for Zookeeper along with Casssandra, Elasticsearch, Redis and Apache NiFi. I am sure there are additional applications that are not compatible with sidecars. Please inform the community if you know of any.
3. Your service may have odd behavior at start or stop time
The app container may start before the sidecar and cause an application failure. A similar challenge can happen at stop time where the sidecar may be stopped before the app container.
Kubernetes lacks a standard way to declare container dependencies. There is a Sidecar Kubernetes Enhancement Proposal (KEP) out there, however it is not yet implemented in a Kubernetes release and will take time for the feature to stabilize. In the meantime, service owners may observe unexpected behavior at startup or at stop.
To help mediate the issue, Istio has implemented a global configuration option for platform owners to delay application start until the sidecar is ready. Istio will soon allow service owner to configure this at the pod level as well.
4. Zero configuration for your service is possible but zero code change is not
One of the main goals for a service mesh project is zero configuration for service owners. Some projects like Istio have added intelligent protocol detection to help detect protocols and ease the onboarding experience to the mesh, however, we still recommend users explicitly declare protocols in production. With the addition of the appProtocol setting in Kubernetes, service owners now have a standard way to configure application protocols for Kubernetes services running in newer Kubernetes versions (e.g. 1.19).
To fully leverage the power of service mesh, zero code changes are unfortunately not possible.
- In order for service owners and platform owners to properly observe service traces, it is critical to propagate the trace headers among the services.
- To avoid confusion and unexpected behavior, it is critical to re-examine retries and timeouts in the service code to see if they should be adjusted and understand their behaviors in relations to the retries and timeouts configured with the sidecar proxies.
- In order for the sidecar proxy to inspect the traffic sent from the application container and leverage the contents intelligently to make decisions such as request based routing or header based authorization, it is critical for service owners to ensure that plain traffic is sent from the source service to the target service and trust the sidecar proxies to upgrade the connections securely.
5. Service owner need to understand nuances of client and service side configurations
Before working on a service mesh, I had no idea there were so many configurations related to timeout and retries from the Envoy proxy. Most users are familiar with request timeouts, idle timeouts and number of retries but there are a number of nuances and complexities:
- When it comes to idle timeouts , there is an idle_timeout under the HTTP protocol that applies to both the HTTP connection manager and the upstream cluster HTTP connections. There is a stream_idle_timeout for a stream to exist with no upstream or downstream activity and even a route idle_timeout that can override the stream_idle_timeout.
- Automatic retries are also complicated. The retries are not simply the number of retries, but the max number of retry attempts that are allowed which may not be the actual number of retries. The actual number of retries depends on the retry conditions, route request timeouts and intervals between the retries which must fall within the overall request timeout and retry budgets.
In a non service mesh world, there is only 1 connection pool among the source and target containers but in a service mesh world, there are 3 connection pools:
- Source container to source sidecar proxy
- Source sidecar proxy to target sidecar proxy
- Target sidecar proxy to target container
Each of these connection pools has its own separate configuration. Karl Stoney has a great blog that explains the complexity and how any of the three could go wrong and what to examine to get them fixed.
Conclusion
I hope the above challenges resonate with you regardless where you are on your adoption of service mesh. I look forward to observing the innovations across all the projects as we work hard to make service mesh as boring but useful as possible.
via: https://www.cncf.io/blog/2020/10/26/service-mesh-is-still-hard/