使用Kubernetes实现高级调度技术
閱讀本文約花費: 14 (分鐘)

使用Kubernetes这样的高级容器编排工具的优势之一就是,它的调度程序非常灵活。这为用户提供了广泛的选择,可以用来指定将Pod分配给满足条件的特定工作站节点的环境,而不仅仅基于节点的可用资源。为了解释Kubernetes如何决定将pod放置在正确的主机上,我们可以看一下Kubernetes master及一些组件的简化图:
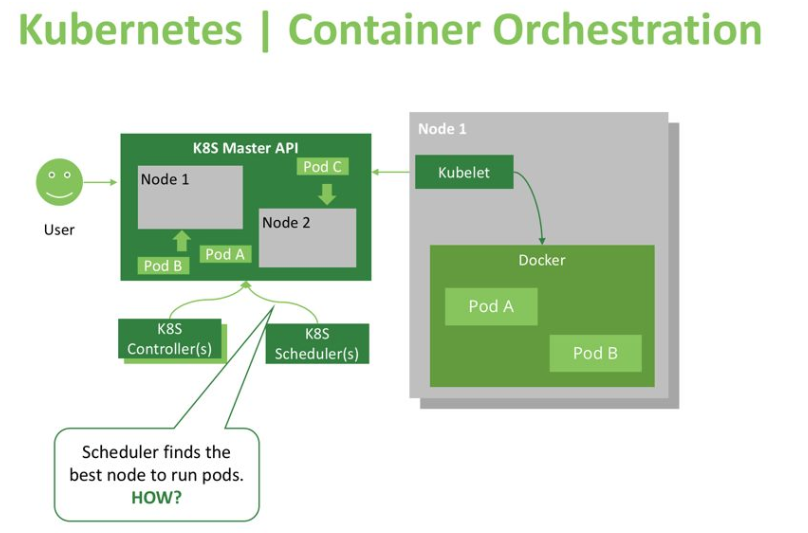
主API(kube-apiserver)是一种提供对集群需求和当前状态进行读/写的工具。像调度程序这样的组件可以使用主API检索当前状态信息,应用一些逻辑和计算,并使用有关所需状态的新信息更新API(例如,指定要将哪个节点安排到新pod,或者指定哪个pod应该移动到另一个节点)。另外,集群用户和管理员可以更新集群状态或通过Kubernetes仪表板查看它,该仪表板对外提供API。CI / CD管道还可以使用API创建新资源或修改现有资源。
其他调用api的主要角色是名为“kubelets”的代理节点,它在工作节点上管理容器运行状态(通常为Docker)。当Kubelet判断出要报告的主机预期状态与其实际状态之间存在差异时,它将启动或终止需要的容器以达到主API描述的目标状态。Kubelets经常查询API,或者观察它们的变化,这就是为什么Kubernetes对更新和更改的响应几乎是即时的。(几秒钟)。
正如我们所看到的,Kubernetes使用控制器模式来维护和更新集群状态,并且调度程序控制器仅负责pod调度决策。调度程序不断监视Kubernetes API来发现未调度pod,并且当发现这类pod时,决定应在哪个节点上调度/放置pod。
启动一个新的pod要经过这三个阶段:
- 节点过滤
- 节点优先级计算
- 实际调度操作
在第一阶段,调度程序将检查哪些节点与此次工作负载兼容。它通过一组过滤器来删除那些不兼容的节点。它将使用以下过滤器:
卷过滤器

通过这些检查,调度程序事先知道哪些节点不能运行pod,因此它会从目标列表中删除这些节点。例如,是与节点在同一可用区中的pod所需的数据卷吗?它可以连接而且不与底层云服务商规则冲突吗?(例如,在AWS中,不可能将EBS卷从一个可用区域添加到到另一个区域中的节点)。另外,需要满足卷定义的拓扑约束(由pod请求的卷可能具有“节点关联性”约束,该约束只允许其添加到特定的一组节点,或者特别禁止它添加到另外一些节点)。
下面是资源过滤器:

以上这些过滤器非常简单。调度程序将检查pod请求的资源是否可用,确保节点上没有压力,如内存不足或磁盘空间不足,并确认是否可以在节点上打开请求的端口。例如,如果pod指定需要绑定到8080端口,但具有相似需求的另一个pod已占用该端口,则该节点将从目标中移除。
最后一组过滤器是关联性选择器:

在本例中,您可以看到调度程序验证pod是否明确声明它需要在特定节点上运行,或者它是否指定pod-affinity(如果需要仅在其他pod存在时运行或避免在同一节点上与特定的pod共同运行)此外,此过滤器还会检查pod是否可以容忍节点的一些不良状况,如dedicated_gpu / maintenance / staging_only(或者用户自定义的情况)或内存压力/不可达/磁盘压力(系统示例应用色素)。容差定义中指定了容差,并允许在具有这些情况的节点上调度容器。换句话说,除了明确声明允许在运行的pod外,其他所有pod都将被拒绝在节点上进行调度或执行。这些是调整Kubernetes调度行为的重要机制。
完成这些过滤步骤后,有可能找不到此Pod的可用节点。在这种情况下,pod将保持不定期,并且会在仪表板中反映,包括运行pod失败的原因(例如,“找不到可以满足这些pod约束的节点”或“没有足够的内存安排pod”)。如果通过过滤,并让您选择几个节点,则调度程序将根据以下参数运行优先级检查:

在此检查完成后,调度程序将计算每个节点的分数,最高分节点将运行该容器。
以下是在pod定义期间控制pod放置的方法列表,按照从基本资源需求到使用自定义调度程序控制器等高级方法的复杂性进行排序:
帮助调度程序做出正确决定的第一个基本方法是设置内存/ CPU请求和限制。请求在调度阶段使用,而在已经运行的pod中使用限制。
我们可以按照以下基本规则避免音量兼容性问题:
- 确保请求的卷与所需的节点位于相同的可用区域中。例如,当您希望运行pod的区域“A”中有一组节点并且需要使用该pod的区域“B”中的某个卷时,请首先确保将这些卷克隆到正确的所在区域,或者在特殊卷所在的区域内旋转几个新节点,以便它可以连接到这些节点。
- 确保节点未达到其容量限制(例如,在Azure云中,有可以连接多少个卷的限制)。
- 不要指定已经连接到单独节点的卷。如果某个容器需要几个卷,但这些容量已经制定连接到另一个主机,则该容器将无法运行,因为无法满足这个条件。
- 通过指定卷可以或不可以连接的节点列表,来使用卷拓扑约束。
另外,我们有几个可用的约束选项,应该在pod定义中指定:
- 直接设置此pod应运行的nodeName。
- 使用nodeSelector来指定节点应该拥有的能够运行该pod的标签。
- Taints(在节点上)和容忍(在Pod上) – 如上所述,Taints是节点状态的指示; 除非他们为这种类型的污点指定“宽容度”,否则没有豆荚会安排在受污染的节点上。一个节点可以有多个污点,并且一个容器可以有多个容忍。
下图显示了污点类型和示例容差定义:

下一个约束机制是可以在pod定义中设置的关联首选项。Affinity目前有两个范围,并且还在开发中。现在只有调度阶段关联可用,如下图所示:
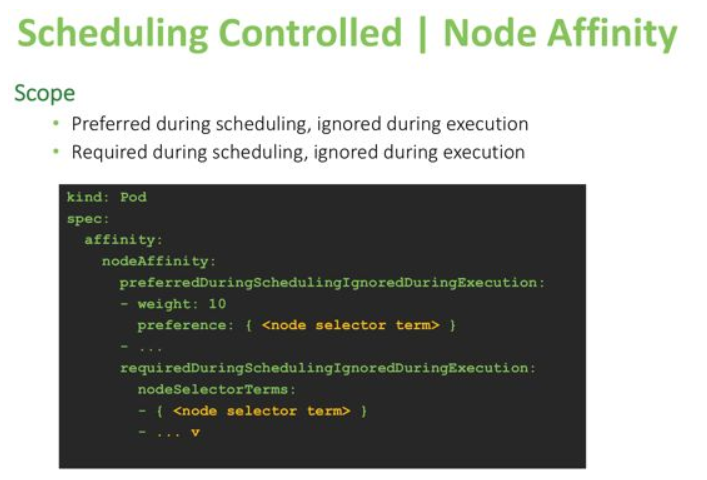
当您使用“preferred during scheduling”选项时,Kubernetes将尽最大努力根据该设置安排pod。如果使用“required during scheduling”,它将强制要求该条件,并且如果不满足该条件,则不会在节点上运行pod。
有几种不同的方法在要运行的节点上指定pod首选项。许多人都很熟悉的简单首选项是“节点选择器”(直接指定特定标签),这将导致只能在具有精确标签值的节点上调度该容器。指定节点首选项的另一种方法是使用节点关系和“节点选择器术语”,它允许使用如下图所示的操作符。这允许用户指定一组灵活的规则,根据该规则来调度或者避免调度。

与节点选择器的严格标签匹配不同,可以在相似性规则的节点选择器术语中使用更灵活的匹配表达式。可以使用匹配表达式运算符将标签值与可能变化列表(“In”运算符)进行比较,或检查标签值是否不是指定列表中的值之一(“NotIn”)。此外,他们可以确定标签是否存在或不存在于节点上,而不考虑其值。最后,他们可以将标签的数值与运算符“Gt”(大于)和“Lt”(小于)进行比较。以下是节点关联性规则的另一个示例:
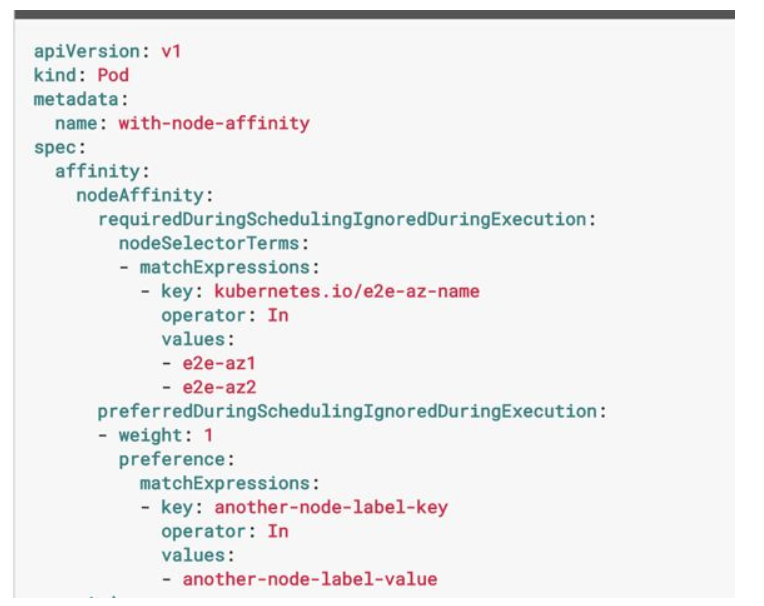
您可以看到,这组规则要求节点将标签“kubernetes.io/e2e-az-name”的值指示可用区域为“e2e-az1”或“e2e-az2”。规则还包含优先选择具有“another-node-label-value”值的自定义标签“another-node-label-key”的节点,这意味着如果存在满足两个约束条件的节点,则它将是运行该pod。
除节点关联设置之外,还有以下定义的inter-pod关联和反关联设置:

使用这些规则,您可以控制彼此相邻的pod位置。有些pod可能会接受与其他类型的pod放在一起,而另外一些pod可能需要避免与特定类型的pod放置在同一台机器上(例如CPU密集型pod,这会导致Kubernetes在同一节点上需要调度工作负载过高,从而性能不佳)。
以下是一个pod关联规则的示例:
- 必须在节点上运行Pod“B”,以便在这里调度pod“A”。
- 首选运行pod“B”的节点,否则,任何节点上都可以。
而此示例显示了pod反关联规则:
- 如果吊舱“B”正在该节点上运行,请勿安排
- 首选pod“B”没有运行的节点,否则在任何节点上都可以运行。
下面是一个引入topologyKey的示例,它是一个标签选择器,将标签关键字定义为“co-location indicator”。为了在整个集群中均匀分配Pod,调度器将尝试选择这些节点上具有不同topologyKey标签值的节点。为了“stack pods as close as possible with one another”(这种调度偏好也存在并在下一步骤中描述),它可以再次基于该topologyKey标签做出判断,这次回优先选择出具有相同标签值的节点。

除了所描述的方法之外,还有其他方式可以修改Kubernetes调度器的行为,例如使用传递给“kube-scheduler”组件(这是运行Kubernetes的主组件之一)的标志设置不同的调度算法。“-algorithm-provider”标志的两个可用选项为:“DefaultProvider”和“ClusterAutoscalerProvider”。“DefaultProvider”尝试在集群中分配容器,以平衡所有节点的负载。并且“ClusterAutoscalerProvider”将尝试在每个节点上防止最多的pod,以获得更好的资源利用率(通常在底层工作器节点基于CPU和内存等消耗资源进行自动伸缩时使用)。
除了算法提供修改之外,还可以使用ConfigMap或文件中定义的策略来提供自己的调度“逻辑”:

这允许您将定制策略传递给调度程序,并且是仅在GitHub中记录的非常先进的功能(甚至Kubernetes官方文档中都没有)。但是,如果你想成为一个Kubernetes“黑客”,你可以在GitHub 的链接页面上找到更多信息,并在这里阅读一个示例策略文件。该策略的每个可用参数决定了算法的流程以及决定了在哪里放置Pod的规则。它在本文档中有描述。为了将你的策略放在文件中,指定“-use-legacy-policy-config = true”+“-policy-config-file”。否则,使用config map和config map命名空间标志来指定目标配置映射来作为策略。
定制调度的另一种方法是针对特定的pod或集群范围,使用您自己的调度程序,您可以使用任何语言编写调度程序。您需要做的就是使用API,如下所示:

在上面的示例中,自定义调度程序需要通过指定的API获取节点和pod,然后选择“phase = Pending”和“schedulerName = your-scheduler-name”的pod。在计算每个pod需要放置的位置之后,调度程序将创建一个Binding对象(用于计算最适合的目标节点,您可以使用在pod定义和节点定义中找到的所有信息,如注释,标签,Docker镜像名称,卷或任何有助于根据您的要求确定pod正确位置的信息)。
为了更好地实现自定义调度程序,您应该观察节点并缓存信息以加快计算速度。一个好的起点是fork当前的调度器,因为它为定制的额外逻辑和函数提供了一个很好的起点。