云上 ARM 实例应用优化之我见
閱讀本文約花費: 22 (分鐘)
发布于:2020 年 8 月 10 日 10:00
ARM 处理器的崛起
过去两个月的科技媒体上关于 ARM 芯片的新闻可谓是高潮迭起,不断的引起人们的关注。
- 首先是在 5 月 11 日,AWS 宣布了基于自研的 Graviton 2 处理器(使用了 ARM Neoverse N1 核心)的第六代 EC2 实例 – M6g 正式发布。这似乎揭开了云计算市场上 ARM 处理器大规模应用的的序幕。
- 紧接着,在今年 6 月 23 日的 WWDC 大会上,Apple 公司宣布了一个影响深远的决定: 计划从 2020 年年底开始,Mac 计算机将会从 Intel 芯片过渡到使用基于 ARM 的自研芯片。也许我们要问,ARM 处理器将将会在桌面设备上复制移动设备的成功吗?
- 第三则新闻是关于高性能计算。6 月 22 日发表的最新的一期 TOP500 榜单上,日本的 Fugaku 系统以 415.5 千万亿次浮点运算的高性能 LINPAC 成绩成为 TOP500 的第一名。而令人惊讶的是这是第一个使用 ARM 处理器的高性能处理系统。
林林总总,即使我们是半导体行业的门外汉也不难得出一个结论 – ARM 处理器不仅仅统治了手机、嵌入式应用这些传统的优势领域,或将在桌面系统、高性能计算尤其是云计算领域扮演越来越重要的角色。
EC2 上的 ARM 处理器
以往我们熟悉的 AWS 所提供的的计算资源所使用的多为 Intel® Xeon® 处理器,例如 Skylake 、Ivy Bridge、Broadwell 以及 Haswell 等 Intel 的多个系列的 CPU。即使在 2018 年新出现的使用了 AMD EPYC 处理器的新的实例类型(M5a、R5a 以及 T3a 等),其 CPU 的架构体系与 Intel 的 CPU 也还同属 “x86-64”(也被称作 x64、AMD64 以及 Intel 64 等) 体系架构。抛开 Intel 与 AMD 半世纪的爱恨情仇,我们可以简单的把这些处理器视作一类。
而这一次 M6g 实例上的处理器却与以往大有不同,采用的是一款名为 Graviton 2 处理器,是由 AWS 使用 64 位 ARM Neoverse N1 内核定制而成。说起 ARM 处理器,我们所了解的是其在移动计算市场的所向披靡,却一直在桌面计算、服务器等对性能要求更高的市场中表现不佳。在过去数年中,ARM 不止一次对高性能处理器领域发起挑战,但多以惨淡的结果收场。而转机就出现在 2019 年初 ARM 发表的 Neoverse N1。对于这一次的发布,ARM 的设计目标就是使其成为一个高性能架构,并重新调校了微架构使其能够以更高的频率运行。在这一点上,ARM 与 AMD、Intel 的路线有所不同,后两家面向高性能平台的处理器产品受制于功耗、面积等因素,频率相比消费级产品要低。但是在 N1 的设计中却恰好相反,处理器的频率相对更高。不仅如此,Neoverse N1 还有一些独特设计,例如缓存的设计。N1 中的 L1 数据缓存和指令缓存部分都是 64KB、4-Way 设计。其中最重要的改变是整个缓存完全采用了一致性设计,它大幅度简化了虚拟环境的实现并且极大地提高了性能。而且这一设计对 ARM 在超大规模计算中保持竞争力也是必须的,因为这可以很方便地扩展核心数量。而这一点在 Graviton2 处理器上表现的淋漓尽致。与第一代 AWS Graviton 处理器相比,Graviton2 处理器实现了性能和功能飞跃,性能提升 7 倍、计算内核数量增加 4 倍,缓存增加 2 倍,内存速度提升 5 倍。

总体来看,Graviton 2 与 N1 平台差异不大,且采用了 TSMC 的 7nm 工艺。当然细微差异还是存在的。例如 Graviton 2 的 CPU 内核的时钟频率较 N1 要低一些。我自己运行一个简单的测试程序得到的 Gravitino 2 时钟频率约为 2.5GHz,并且 L3 缓存为 32MB 而不是公版的 64MB。该系统由 8 通道 DDR-3200 内存控制器支持,并且 SoC 支持 64 个 PCIe4 通道用于 I/O。至于这款芯片的功耗,考虑到 ARM 宣称的 64 核 2.6GHz CPU 的功耗约为 105W,以及 Ampere 最近披露的其 80 核 3GHz N1 服务器芯片的功耗为 210W。ANANDTECH 对 Graviton 2 给出的的估算结果是功耗大致位于 80 瓦至之 110 瓦之间。
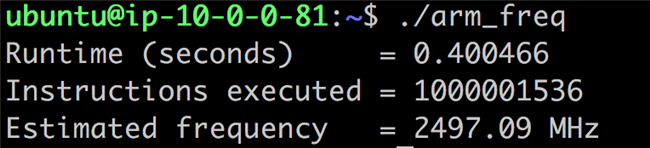
现代的 CPU 存在着核心数量越来越多的趋势。随着系统中的核心数量的增多,服务器芯片中的内存性能成为了影响性能至关重要的因素。借助 8 个 DDR4-3200 内存控制器, Graviton 2 芯片具有先进的内存功能,理论上可提供高达 204GB/s 的峰值带宽。在 ANANDTECH 的测试中, Graviton2 的单个 CPU 内核能够以高达 36GB/s 的速度传输写入数据。内存加载速度高达 18.3GB/s,内存复制达到了令人印象深刻的 29.57GB/s,这是测试中 AMD 系统的两倍以上,几乎是 Intel 系统的三倍。关于 ANANDTECH 的这份测试报告,可以访问这个链接来了解 https://www.anandtech.com/print/15578/cloud-clash-amazon-graviton2-arm-against-intel-and-amd 。
AWS Graviton2 处理器的性能
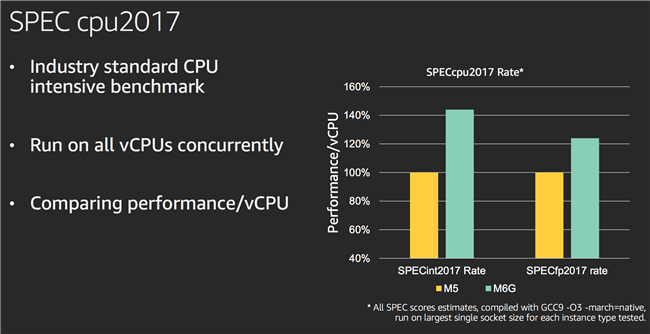
与一年前发布的第一代 AWS Graviton 处理器相比,Graviton2 处理器不管在性能还是功能上都实现了一次巨大的飞跃。它们都支持 Amazon EC2 M6g、C6g 和 R6g 实例,而且与当前这一代基于 x86 的实例相比,这些实例为各种工作负载(包括应用程序服务器、微服务、高性能计算、电子设计自动化、游戏、开源数据库和内存中的缓存)提供高达 40% 的性价比提升。AWS Graviton2 处理器也为视频编码工作负载提供增强的性能,为压缩工作负载提供硬件加速,并为基于 CPU 的机器学习推理提供支持。它们可以提供高 7 倍的性能、多 4 倍的计算核心、快 5 倍内存和大 2 倍缓存。
在 AWS re:Invent 2019 大会上,EC2 产品团队分享的几组处理器 Benchmark 的结果就让人兴奋不已。

此外,在今年 3 月份 KeyDB 分享了它们针对 M6g vs M5 实例上的性能对比测试。众所周知,KeyDB 是 Redis 的多线程超集,由于其先进的体系结构,具备了很好的性能表现。
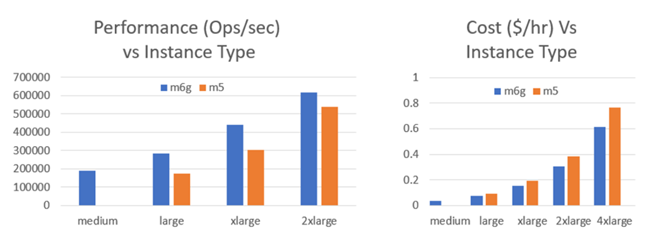
他们的测试结论是这样的 –
“M5 实例使用 Intel Xeon Platinum 8175 处理器,与其他大多数可用实例类型相比,它们通常为我们带来非常好的效果。令我们震惊的是,在较小的使用 AWS Graviton2 处理器的 M6g 实例上,与现有的 KeyDB M5 实例相比,获得了如此巨大的收益。
m6g.large 比 m5.large 快 1.65 倍,而 m6g.xlarge 则比 m5.xlarge 快 1.45 倍。随着内核数量的增加,两种产品之间的差距开始缩小。但是,我们仍在研究 m6g.2xlarge 和 m6g.4xlarge 的性能,因为我们相信可以将性能水平提高到相同的倍数。在此测试中,我们没有针对 M6g 进行任何调整,因此我们对即将到来的结果感到乐观。”
而在今年的 5 月 15 日,在测试工具市场久负盛名的 Phoronix 发表了一篇关于使用 Graviton2 CPU 的新 M6g 实例的性能测试的文章。他们使用 M6g 实例作为基准。然后将这些实例与较早的 A1Graviton 实例进行比较。在 Intel Xeon 方面,选择了 M5 实例,在 AMD EPYC 方面选择的是 M5a 实例。该测试报告的全文的链接在这里, https://www.phoronix.com/scan.php?page=article&item=amazon-graviton2-benchmarks&num=1 。
这里仅仅撷取其中的部分结果以供各位参考:
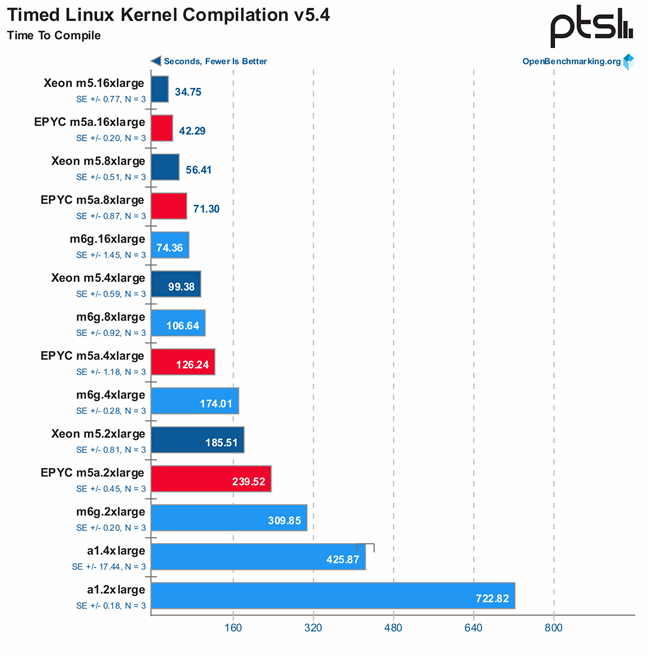
- Linux Kernel(V5.4) 的编译时间,数字越小越好
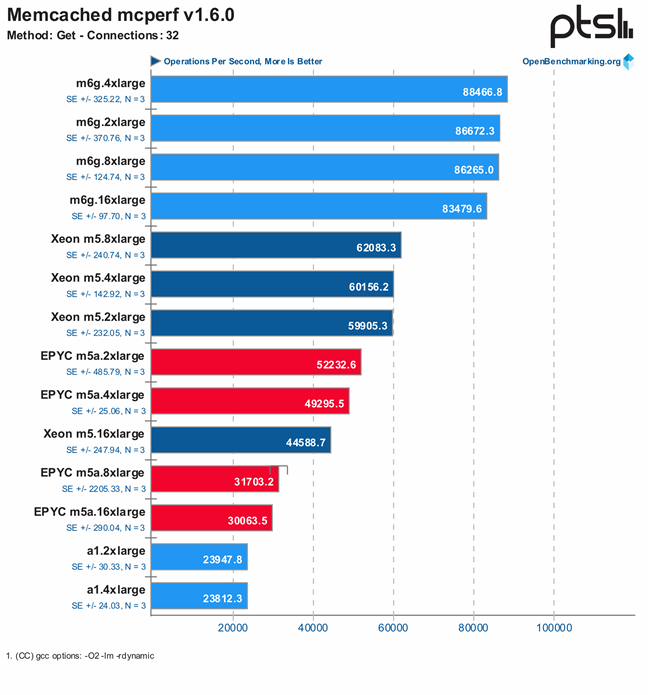
- Memcached mcperf v1.6.0, 数字越大越好
EC2 实例吞吐量的基础概念 – vCPU 与核心
除了实例类型之外(例如 M5、C4),其它用于描述实例能力的最重要的指标就是其 vCPU 的数量。所谓的 vCPU 是 Virtual Central Processing Units 的缩写。vCPU 本质上是指虚拟机上可用的逻辑 CPU 的内核。但 EC2 的逻辑 CPU 计算方法却并非是基于物理上的 CPU 内核。准确的说,并发线程的数量即为 EC2 vCPU 的数量。例如,默认情况下,M5.xlarge 实例类型有两个 CPU 内核,每个内核支持两逻辑个线程,这样该类型实例的 vCPU 的数量即为 4 个。EC2 实例范围通常从 1 个 vCPU 到最多 128 个,常见的实例的 vCPU 的数量多为 2、4、8、16、32、48、64 和 96 等。
Graviton 2 是不带 SMT 的单路 64 核平台。所谓的 SMT(Simultaneous multithreading) 的含义其实就是我们熟知的超线程技术。简单来说,SMT 技术可以在一个实体 CPU 中提供两个逻辑线程,通过分享处理器的资源来提高性能。在 Intel 的 CPU 中类似的技术被称作 Hyper-Threading,或者简称 HT。目前,Graviton 2 最大可用 vCPU 实例大小为就是 64。
但是,这也意味着在谈论例如 64 个 vCPU 实例的时候(在 EC2 中的规格称为 16xlarge),对于 Graviton2 实例我们将获得 64 个物理核心,而对于 AMD 或 Intel 系统,我们将仅获得 32 个具有 SMT 的物理核心。这确实有一点“不公平”的味道,但是考虑到规格描述的一致性,这一点差别只好被忽略了。
ARM 实例的应用优化
Graviton 2 目前被用于 EC2 家族中的 M6g、C6g 以及 R6g 实例。其中,
- M6g 实例用于具有 CPU、内存和网络资源平衡的通用工作负载
- C6g 实例用于计算优化的工作负载,例如视频编码、建模和游戏服务器
- R6g 实例用于内存优化的工作负载,可处理内存中的大型数据集(如数据库)
与我们熟悉的型 x86-64 架构不同,Graviton 2 支持 ARM V8.2 和其它几个架构扩展。特别要强调的是,Graviton2 支持 用于原子操作的 LSE (Large System Extension) 指令集的扩展,可以提高大系统之间的锁定和同步性能。此外,它还支持 FP16 和用于机器学习的 INT8 等。毫不夸张的说,这一次 Graviton2 给我们带来的足够的惊喜。但不可否认的是,ARM 处理器的体系结构与以往我们所熟悉的 x86-64 处理器的差异还是非常之大的。简而言之,如果我们不掌握针对 ARM 处理器的应用优化的方法,我们所看到的这一切性能上的提升不过是镜花水月。
C/C++ 代码在 Graviton 上的优化
C/C ++ 代码将极大的受益于设置优化代码的编译器标志并启用 ARM 特定的功能。
- GCC/G++ 编译选项CPUGCCLLVMGraviton-march=armv8-a+crc+crypto-march=armv8-a+crc+cryptoGraviton 2-march=armv8.2-a+fp16+rcpc+dotprod+crypto-march=armv8.2-a+fp16+rcpc+dotprod+crypto-march 编译项告诉编译器应该为系统的处理器架构生成什么代码,即向编译器声明应该为某种 CPU 架构生成代码。不同的 CPU 具有不同的功能,支持不同的指令集,执行代码的方式也不同。march 标志将指示编译器为系统的 CPU 生成特定的代码,包括 CPU 的所有功能、特性、指令集、异常等等。** 需要注意的一点是,对于 GCC 7.x 和 8.1、8.2 和 8.3 等版本 -march=native 不能正确地检测 Graviton 2 体系架构。务必请使用 -march=armv8.2-a 而不是 -march=native。GCC 9.x 以及 10.x 则可以很好的识别 Graviton 2 的体系结构。目前 Amazon Linux 2 缺省安装的 GCC 版本是 7.3.1,而 Ubuntu 20.04 缺省安装的 GCC 版本为 9.3.0,还可以通过 sudo apt install gcc-10 安装 GCC 10.0.1。CPUGCC < 9GCC >= 9Graviton-mtune=cortex-a72-mtune=cortex-a72Graviton 2-mtune=cortex-a72-mtune=neoverse-n1-mtune 此选项指定 GCC 为其调整代码性能对应特定目标 ARM 处理器类型,可以通过使用这个选项来实现更好的性能。此外,此选项可以指定 GCC 为 big.LITTLE 系统调整代码的性能。所谓的 big.LITTLE ,是 ARM 的异质运算多核心处理器技术。具体做法是将比较耗电、但运算能力强的处理器核心组成的“big 集群”与低耗电、运算能力弱的处理器核心组成的“LITTLE 集群”结合在一起,这些处理器核心共享存储器区段,并能够在不同的 CPU 集群之间在线实时分派、切换负载。
- Large-System Extensions (LSE)Graviton 2 处理器支持 ARMv8.2 指令集。LSE 则提供低成本的原子操作。原因是是 LSE 提高了 CPU 对 CPU 的通信、锁和互斥的系统吞吐量。当使用 LSE 而不是加载 / 存储独占时,这种改进可以提升一个数量级。POSIX 线程库需要 LSE 原子指令。LSE 对于锁定和线程同步例程很重要。例如 Amazon Linux 2 与 Ubuntu 20.04 均发布了一个支持 LSE 指令的 libc 库。编译器需要为使用原子操作的应用程序生成 LSE 指令。例如,像 PostgreSQL 这样的数据库代码包含原子结构 ; 带有 std:: 原子语句的 C++11 代码转换为原子操作。GCC 的 -march=armv8.2-a 标志支持所有由 Graviton2 支持的指令,包括了 LSE。如果需要满足对于 LSE 的支持,还需要 libc 的版本要高于 2.3.0。目前 Amazon Linux 2 的 glibc 的版本为 2.26, Ubuntu 20.04 的 libc 的版本为 2.31。
Java 程序在 Graviton 上的优化
Java 是一种通用编程语言。 编译后的 Java 代码可以在支持 Java 的所有平台上运行,而无需重新编译。 Java 应用程序通常被编译为可在任何 Java 虚拟机(JVM)上运行的字节码,而与基础计算机体系结构无关。Java 受到了包括 ARM 在内的广泛的支持,并且在 ARM64 上是开箱即用的。 Amazon Corretto 是一种免费的,跨平台的,可立即投入生产的 Open Java Development Kit(OpenJDK)发行版,支持由 Graviton 驱动的实例。如要获得 Amazon Corretto 的安装包请访问这个链接 https://aws.amazon.com/corretto 。
注意:下载时需要选择 aarh64 的安装包。
此外,OpenJDK 也提供了对于 arm64 平台的支持。在 Graviton 处理器上,可以选择安装 openjdk-8、openjdk-11、openjdk-13 以及 openjdk-14 等不同的 JDK 版本。
Java JAR 可以包含特定于体系结构的共享库。一些 Java 库检查是否找到了这些共享库,是否使用 JNI 调用了本机库,而不是依赖于该函数的通用 Java 实现。尽管代码可以工作,但是如果没有 JNI,性能可能会受到影响。
检查 JAR 是否包含此类共享库的一种快速方法是简单地将其解压缩,并检查是否有任何结果文件是共享库,以及是否缺少 aarch64(arm64)共享库:复制代码
$ unzip foo.jar$ find . -name "*.so" | xargs file
Python 程序在 Graviton 上的优化
Python 程序解释执行的特点需要我们使用的 Python 解释器可以很好适配于 Graviton 处理器。对于 Python 解释器优化的关键是确保解释器使用了 PGO 和 LTO 等优化编译的选项。获得 Python 解释器编译选项的方法很简单,
python3 -c “import sysconfig; print(sysconfig.get_config_var(‘CONFIG_ARGS’))”
| Amazon Linux 2 | Ubuntu 20.03 |
|---|---|
| Python 3.7.6 | Python 3.8.2 |
| ‘–build=aarch64-koji-linux-gnu’ ‘–host=aarch64-koji-linux-gnu’ ‘–program-prefix=’ ‘–disable-dependency-tracking’ ‘–prefix=/usr’ ‘–exec-prefix=/usr’ ‘–bindir=/usr/bin’ ‘–sbindir=/usr/sbin’ ‘–sysconfdir=/etc’ ‘–datadir=/usr/share’ ‘–includedir=/usr/include’ ‘–libdir=/usr/lib64’ ‘–libexecdir=/usr/libexec’ ‘–localstatedir=/var’ ‘–sharedstatedir=/var/lib’ ‘–mandir=/usr/share/man’ ‘–infodir=/usr/share/info’ ‘–enable-ipv6’ ‘–enable-shared’ ‘–with-computed-gotos=yes’ ‘–with-dbmliborder=gdbm:ndbm:bdb’ ‘–with-system-expat’ ‘–with-system-ffi’ ‘–enable-loadable-sqlite-extensions’ ‘–with-dtrace’ ‘–with-lto’ ‘–with-ssl-default-suites=openssl’ ‘–without-ensurepip’ ‘–enable-optimizations’ ‘build_alias=aarch64-koji-linux-gnu’ ‘host_alias=aarch64-koji-linux-gnu’ ‘CFLAGS=-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong –param=ssp-buffer-size=4 -grecord-gcc-switches -D_GNU_SOURCE -fPIC -fwrapv ‘ ‘LDFLAGS=-Wl,-z,relro -g ‘ ‘CPPFLAGS= ‘ ‘PKG_CONFIG_PATH=:/usr/lib64/pkgconfig:/usr/share/pkgconfig’ | ‘–enable-shared’ ‘–prefix=/usr’ ‘–enable-ipv6’ ‘–enable-loadable-sqlite-extensions’ ‘–with-dbmliborder=bdb:gdbm’ ‘–with-computed-gotos’ ‘–without-ensurepip’ ‘–with-system-expat’ ‘–with-system-libmpdec’ ‘–with-dtrace’ ‘–with-system-ffi’ ‘CC=aarch64-linux-gnu-gcc’ ‘CFLAGS=-g -fstack-protector-strong -Wformat -Werror=format-security ‘ ‘LDFLAGS=-Wl,-Bsymbolic-functions -Wl,-z,relro -g -fwrapv -O2 ‘ ‘CPPFLAGS=-Wdate-time -D_FORTIFY_SOURCE=2’ |
可以看得出来,在不同的 Linux 分发版本中,Python 解释器的版本以及优化方法存在一些差异。对比起来 Ubuntu 20.04 的 Python 解释器无论是 Pystone 还是 Pytest-benchmark 都要表现的更好一些。
NumPy 与 SciPy
对于一些场景,Python 应用需要使用 NumPy 以及 SciPy。通常我们通过 pip3 install numpy scipy 安装其二进制版本。一些场景下,使用 BLIS 对 SciPy 和 NumPy 工作负载进行基准测试可以确定额外的性能改进。
注:BLIS 是一个可移植的软件框架,用于实例化高性能 BLAS 高性能稠密线性代数库。
- 在 Ubuntu 上用 BLIS 安装 NumPy 和 SciPy在 Ubuntu 上安装 python3-numpy 与 python3-scipy 程序包将安装带有 BLAS 和 LAPACK 库的 NumPy 和 SciPy。用 BLIS 和 OpenBLAS 在 Ubuntu 和 Debian 上安装 SciPy 和 NumPy:复制代码
sudo apt -y install python3-scipy python3-numpy libopenblas-dev libblis-devsudo update-alternatives --set libblas.so.3-aarch64-linux-gnu \/usr/lib/aarch64-linux-gnu/blis-openmp/libblas.so.3在 blas 与 lapack 之间进行切换复制代码sudo update-alternatives --config libblas.so.3-aarch64-linux-gnusudo update-alternatives -config liblapack.so.3-aarch64-linux-gnu
PyPy
此外,2019 年 7 月 25 日,PyPy 宣布了对于 Aarch64 架构的支持。在基于 Graviton 处理器的 A1 实例上进行的性能测试。从结果来看,PyPy 对于 Python 程序性能的提升是非常显著的。
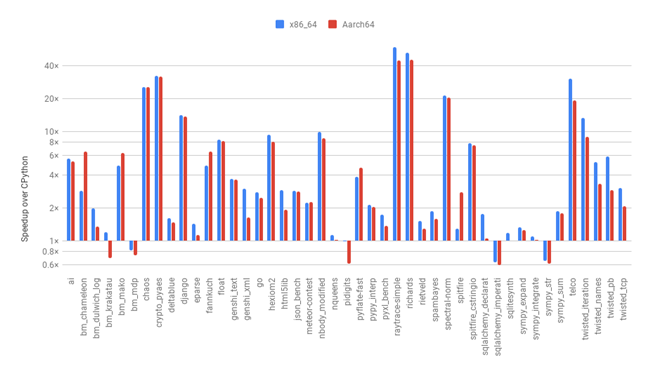
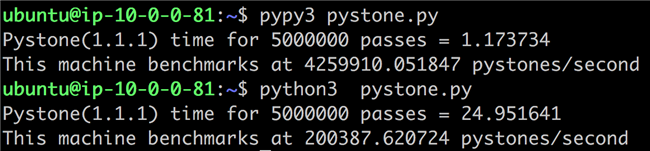
在一台基于 Graviton 2 的 m6g.2xlarge 的实例上运行 Pystone,PyPy 的性能是 CPython (Python 3.8.2)的 21 倍!! 性能的提升是非常的惊人了。
Go 程序在 Graviton 上的优化
Go 是一种静态类型的编译型程序语言。Go 支持开箱即用的 arm64,可以在所有常见的发行版中使用。Go 最新的升级提高了性能,所以请确保使用最新版本的 Go 编译器和工具链。目前 Go 的最新版本是 1.14,而 Amazon Linux 2 与 Ubuntu 20.04 提供的安装包的版本均为 1.13。在 Ubuntu 环境下,安装 Go 最新版本的一个简单的途径还可以考虑通过 snap 进行安装。在 snap 中提供的 Go 的版本为 1.14.6。
Go 1.16
Go 的下一个版本 1.16 预计将于 2021 年初发布。预计 Go 编译器将会通过以下列出的几项特性来提高 ARM 架构下程序的性能。
- ARMv8.1-A Atmoics 指令,可显着提高 Graviton 2 上的互斥公平性和速度,以及带有 v8.1 和更新指令集的现代 Arm 内核。
- 复制性能得到改善,尤其是当地址未对齐时。
关于系统优化的话题总是会有太多的内容值得探讨。随着新的基于 ARM 的实例的普及,越来越多的开发者一定会遇到应用优化的问题。这篇博客权当是抛砖引玉之作,期待你们的经验与反馈。我的邮箱地址是 [email protected] 。
作者介绍:
费良宏
费良宏,AWS Principal Developer Advocate。在过去的 20 多年一直从事软件架构、程序开发以及技术推广等领域的工作。他经常在各类技术会议上发表演讲进行分享,他还是多个技术社区的热心参与者。他擅长 Web 领域应用、移动应用以及机器学习等的开发,也从事过多个大型软件项目的设计、开发与项目管理。目前他专注与云计算以及互联网等技术领域,致力于帮助中国的 开发者构建基于云计算的新一代的互联网应用。
原文链接:
https://amazonaws-china.com/cn/blogs/china/optimization-of-arm-example-application/