如何对 ElasticSearch 集群进行压力测试
閱讀本文約花費: 14 (分鐘)
当 ElasticSearch 的业务量足够大,比如每天都会产生数百 GB 数据的时候,你就会自然而然的需要一个性能更强的 ElasticSearch 集群。特别是当你使用的场景是一些典型的大量数据进入的场景,比如网站日志、用户行为记录、大型电商网站的站内搜索时,一个强劲的 ElasticSearch 是必不可少的组件。在这样的场景下,如何找到一组合适的 ElasticSearch 集群?如何评估 ElasticSearch 集群的性能,就成为了一个十分重要的因素。
用什么 ElasticSearch 进行压力测试?
对于 ElasticSearch 性能测试和压力测试方面,其实有很多不同的方案,比如:
- Rally:Rally 是 Elastic 官方针对于 ElasticSearch 的宏观测试工具。
- ESPerf:一个基于 Golang 编写的 ElasticSerch 性能测试工具
- Elasticsearch Stress Test:由著名的 ElasticSearch 服务提供商 Logzio 开发的性能测试工具
除了这些定制化的工具意外以外,ElasticSearch 也可以借由其 Restful API 来使用Load Runner、JMeter等老牌工具进行测试,这些工具零零散散,各有各的用法和用途,不过,对于广大开发者而言,还是官方出的 Rally 更令人满意。
在本篇文章中,将会使用 Rally 来完成 ElasticSearch 集群的压力测试
Rally 作为官方出品的工具,来自官方的信任加成让他成为各家进行压力测试的首选工具。其次, Rally 官方给出了多种默认的数据集(Tracks)。如果你的使用场景覆盖在这些数据集(比如HTTP 访问事件数据、地理名称数据、地理坐标点数据、HTTP 请求日志、问答场景、打车记录等场景)中,可以直接使用已有的数据集,来完成测试,而无需制造测试数据。
即使你的场景比较特殊,无法被官方的数据集所覆盖,也依然可以根据自己的线上数据,来创建数据集,确保测试效果的准确。
如何使用 Rally 进行测试?
在了解了 Rally 后,来具体看一看 Rally 的使用。
测试前的准备
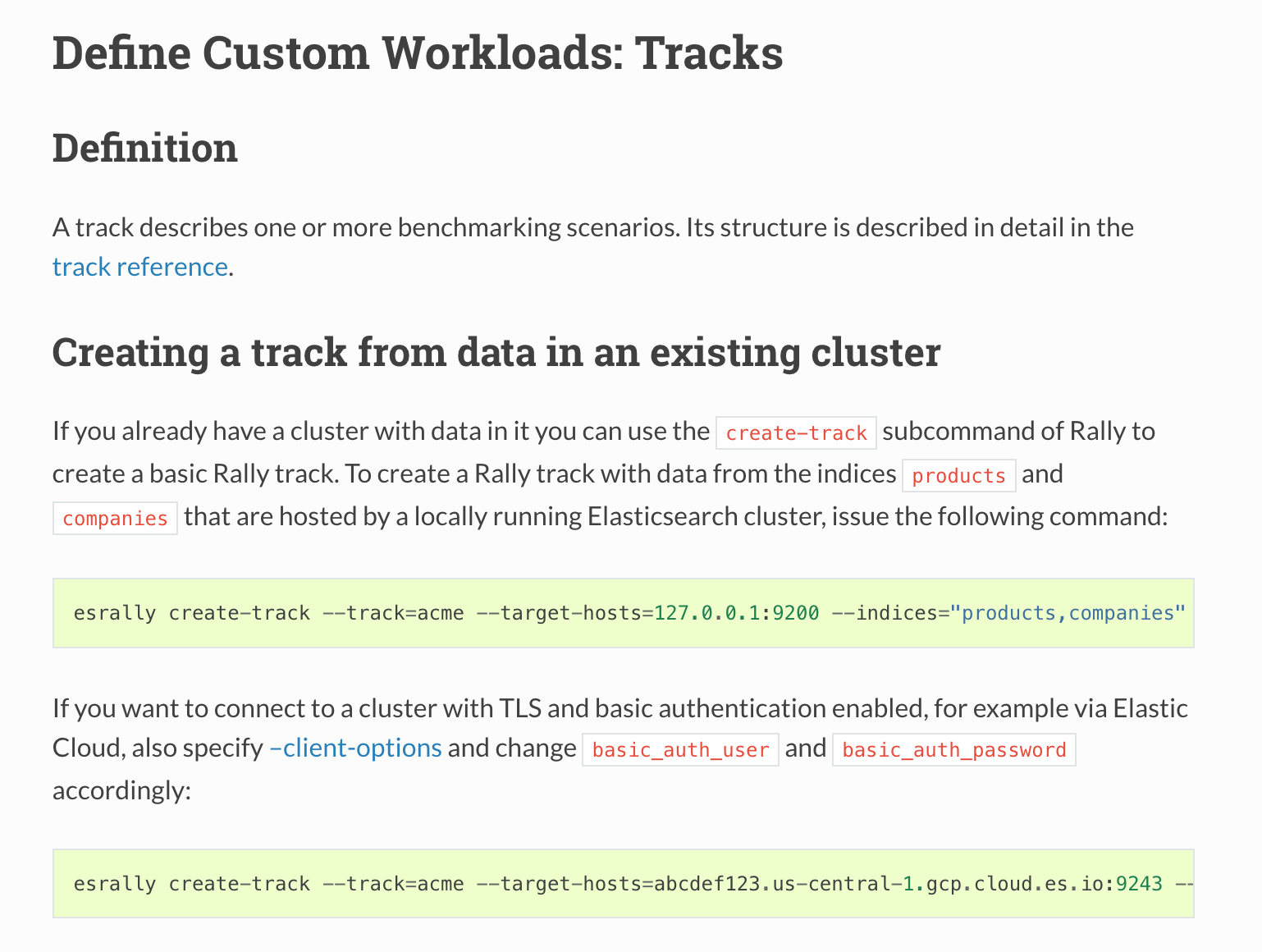
关于 Rally 的基本安装,这里就不再介绍,总的来说十分简单,在配置好了 JDK 和 Python 环境以后,只需要执行pip install rally 就可以完成安装。如果你的环境复杂,希望以一个更简单的方式来运行,你也可以选择使用 Docker 来运行 Rally ,进行测试。关于更多的安装方式,你可以参考 Rally 的安装文档.
在安装完成了 Rally 后,就可以开始进行 ElasticSearch 的测试。
在测试前,你需要先了解一些基本概念
- race:在 Rally 中,每一次测试都可以称之为 race
- car: 在 Rally 中,每一个参与测试的集群,都可以称之为 car ,不同的集群就是不同的 car,如果你是在选配置,则可以通过切换 car 来设置不同配置的测试。
- track: 在 Rally 中,每一次测试用的数据,都可以称之为 Track,不同的 Track 意味着不同的测试数据。
- challange: 在 Rally 中,每一个 challange 意味着一个不同的测试场景,具体的场景则代表着 ElasticSearch 所执行的操作。
在了解测试的基本概念后,就可以开始进行压力测试。
进行压力测试
测试设备
由于本次测试实际上是一次选型的过程,在测试之前,我曾阅读了 Elastic 官方的权威指南中的硬件部分.在其文档中提供了对于运转 ElasticSearch 集群设备的推荐配置。
- 64 GB 内存的机器是非常理想的, 但是32 GB 和16 GB 机器也是很常见的。少于8 GB 会适得其反(你最终需要很多很多的小机器),大于64 GB 的机器也会有问题, 我们将在 堆内存:大小和交换 中讨论。
- 如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
- 如果你负担得起 SSD,它将远远超出任何旋转介质(注:机械硬盘,磁带等)。 基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起,SSD 是一个好的选择。
- 通常,选择中配或者高配机器更好。避免使用低配机器, 因为你不会希望去管理拥有上千个节点的集群,而且在这些低配机器上运行 Elasticsearch 的开销也是显著的。
因此,我选择了原本打算购买的三家厂商(阿里云、腾讯云、UCloud)的设备进行测试,在具体的配置层面,则在各家购买四台 8C64G 100GBSSD磁盘的的云主机来进行测试。

测试环节
1. 构建集群
在进行测试前,需要先对已有的三台设备搭建集群,并配置集群链接,确保集群正常工作。集群搭建的部分,你可以参考官方文档中的Add and remove nodes in your cluster部分。
2. 执行测试命令
在完成了集群的建设后,测试就简单很多,只需要执行命令,便可以对已经建设好的集群进行测试,比如:
esrally --track=pmc --target-hosts=10.5.5.10:9200,10.5.5.11:9200,10.5.5.12:9200 --pipeline=benchmark-only
执行完命令后,接下来就是漫长的等待,根据机器的配置和集群等
3. 获得测试结果
在执行了测试命令后,测试完成后,你就可以获得相应的测试结果。不过,为了方便进行对比和查看,你可以在测试的命令中加入参数,从而实现将测试结果导出为特定的格式。
比如,执行这样的测试命令,就可以获得 CSV 格式的测试数据
esrally --track=pmc --target-hosts=10.5.5.10:9200,10.5.5.11:9200,10.5.5.12:9200 --pipeline=benchmark-only -report-format=csv --report-file=~/benchmarks/result.csv
当你得到了 csv 的结果后,就可以对数据进行分析和对比了。
如何查看 Rally 的测试结果
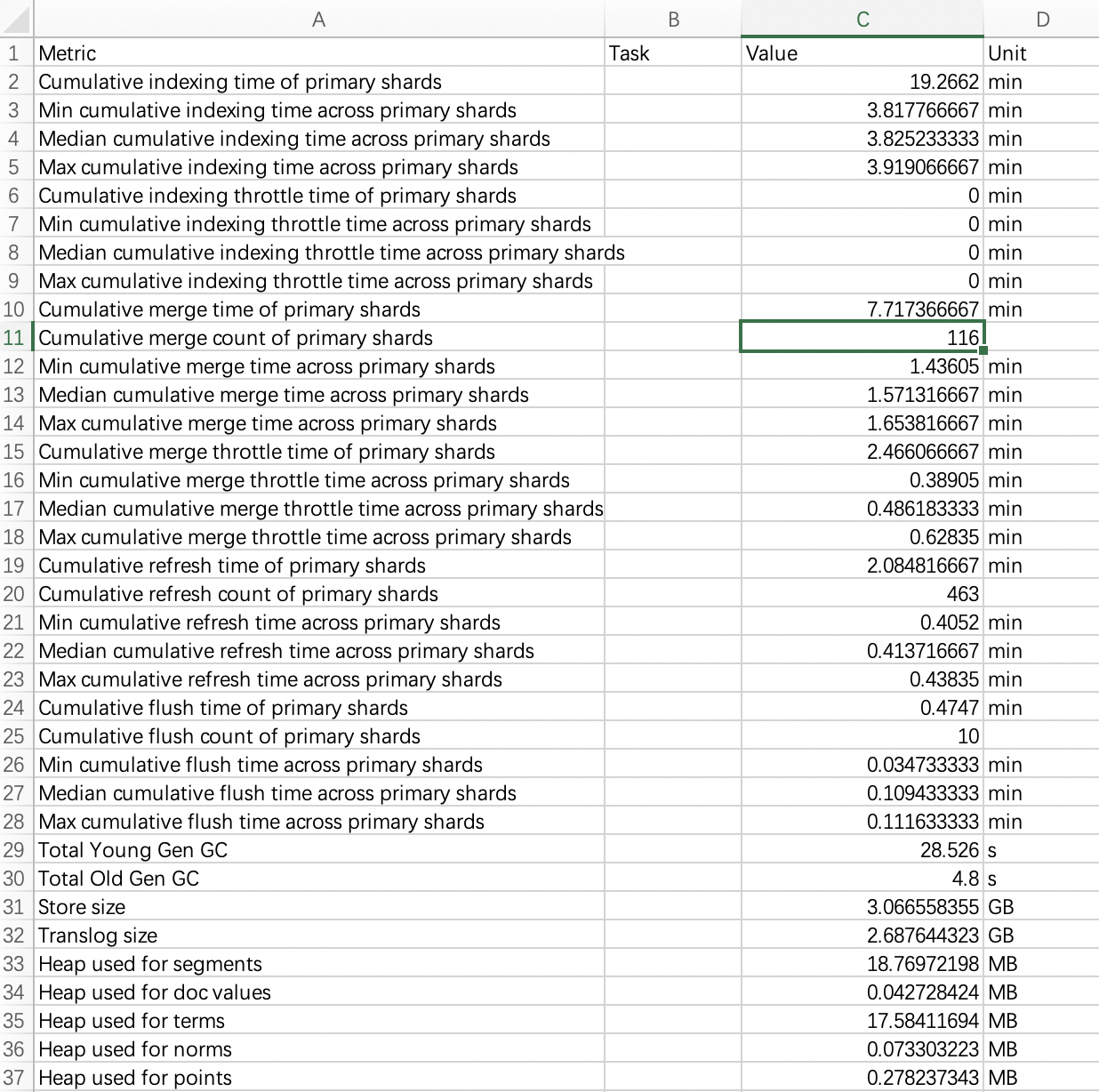
当我们对 Rally 执行测试以后,我们会拿到大量的数据,而具体这些数据应该如何来看呢?接下来我们一一来看。
如何理解 Rally 的数据
Rally 导出的数据共有 4 列,分别是 Metric(维度)、*Task(任务)*、Unit(单位)和*Result(结果)*。
我们可以将数据按照 Task 进行切分,你可以得到若干组结果,如:
- 没有 Task 的宏观数据
- index-append 组数据
- index-stats 组数据
- node-stats 组数据
- phrase 组数据
- …
不同的组意味着 ElasticSearch 在不同场景下的应用,因此,你在对比时,需要按照分组来看数据。而分组内部的数据,就简单了许多,除了宏观数据以外,其他各组的数据基本上都是一个模式的,具体可以分为以下 14 组数据。
- Min/Median/Max:本组测试的最小吞吐率、中位吞吐率和最大吞吐率,单位为 ops/s ,越大越好。
- 50th/90th/99th/100th percentile latency: 提交请求和收到完整回复之间的时间段,越小越好
- 50th/90th/99th/99.9th/100th percentile service time:请求处理开始和接收完整响应之间的时间段,越小越好
- error rate:错误率,错误响应相对于响应总数的比例。任何被 Elasticsearch Python 客户端抛出的异常都被认为是错误响应(例如,HTTP 响应码 4xx、5xx或者网络错误,如网络不可达)。
当你能够理解数据的划分方式后,对于 Rally 返回的众多数据就比较好理解了。接下来,我们以实际例子来看 Rally 返回的数据。
如何理解 Rally 返回的宏观测试数据
这里以我测试的数据为例。
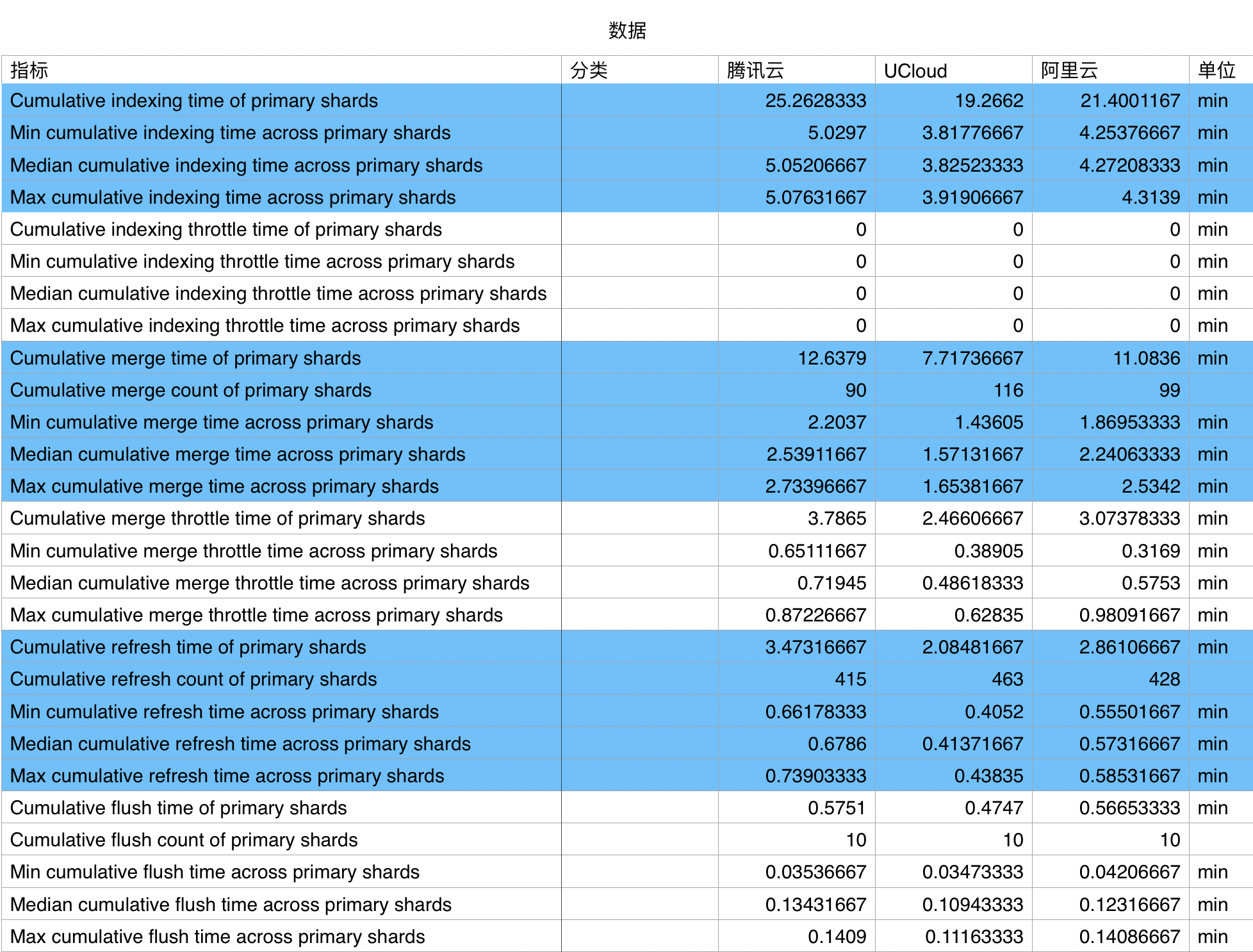
根据每组数据对应的不同操作,我们可以将其数据分为若干组,这里我将数据按照颜色进行了一个基础的划分,从上到下依次为:
- 索引时间
- 索引节流时间
- 合并时间
- 合并节流时间
- 刷新时间
- 重刷时间
首先,先看第一组的索引时间,索引时间共有四个指标:
- Cumulative indexing time of primary shards: 主分片累计索引时间
- Cumulative indexing time across primary shards:跨分片累计索引时间
- Cumulative indexing throttle time of primary shards:主分片累计节流索引时间
- Cumulative indexing throttle time across primary shards:跨分片累计节流索引时间
这四个指标说明了 ElasticSearch 在进行数据处理所需要的索引时间,因此,时间越短越好。
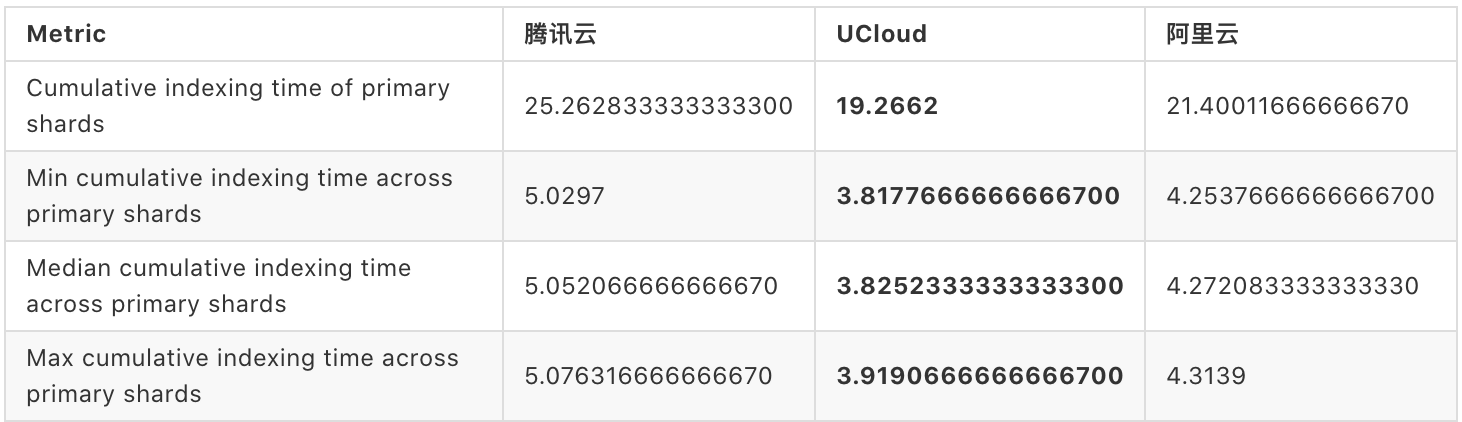
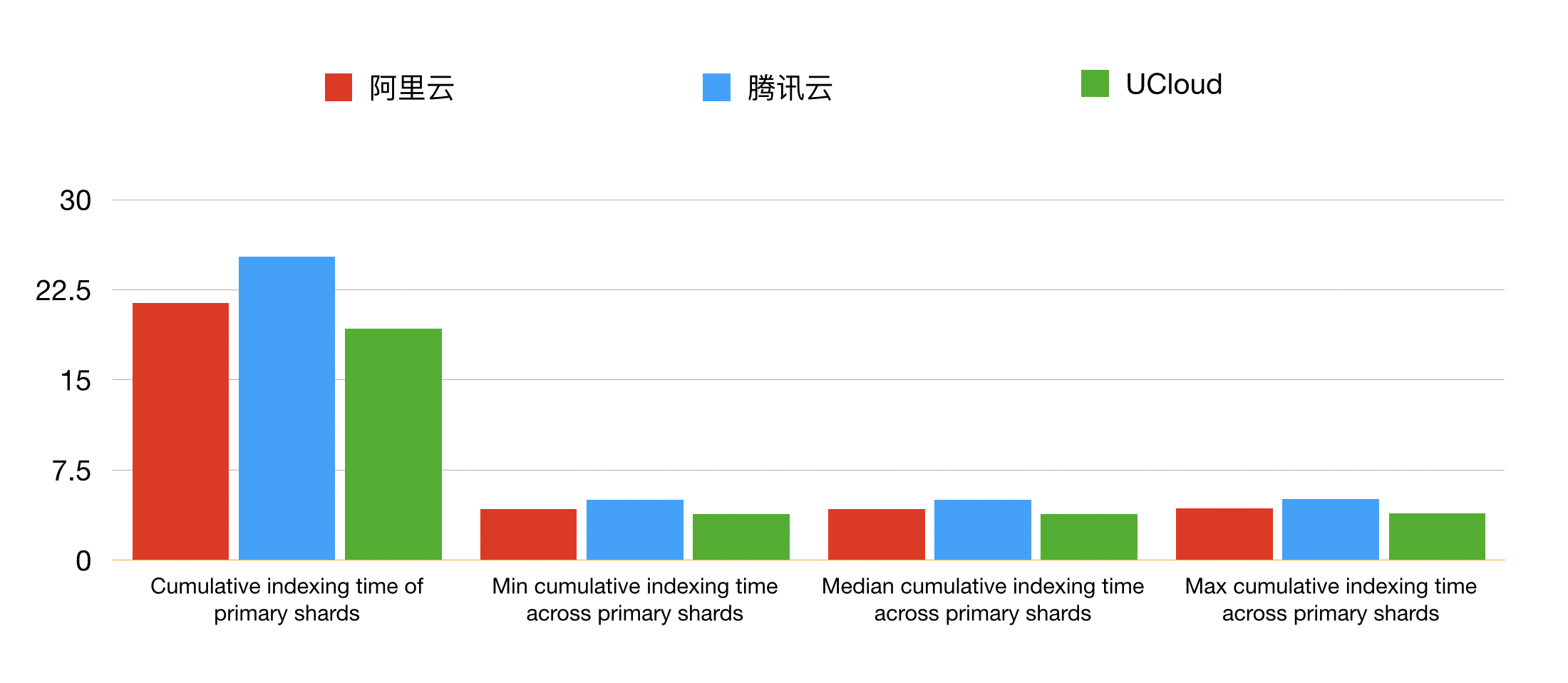
在本组测试结果中,腾讯云的计算时间耗费最长,阿里云可以在腾讯的基础之上,有约 16 % 的性能提升,UCloud 则在腾讯云的基础之上提升了 24%。
在测试过程中,会因为机器的性能等因素,而造成实际测试时间的不同。在这三组中,阿里云是最神奇的一个,因为它测试时间达到了6个小时。而 UCloud 和腾讯云则分别在 3 小时和 4 小时左右,实际的测试体验还是有很大的差距。如果你要复现相应的实验,建议你在早上进行,这样出测试结果的时候刚好还在白天。
接下来看合并时间的数据
- Cumulative merge throttle time of primary shards:主分片累计节流合并时间
- Min cumulative merge throttle time across primary shards:主分片累计节流合并时间
- Median cumulative merge throttle time across primary shards:主分片累计节流中位合并时间
- Max cumulative merge throttle time across primary shards:主分片累计节流最大合并时间
合并时间组结果类似于索引时间组,不同的是测量的数据 Merge 时间。和 index 类似,时间越短越好,合并数量越大越好。
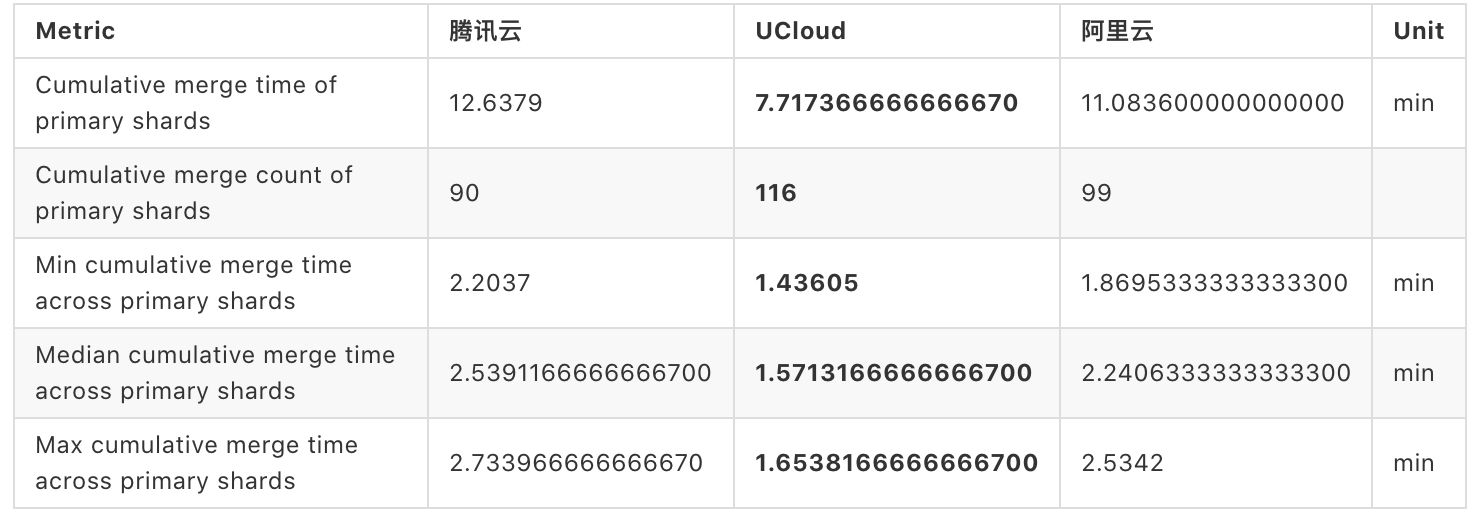
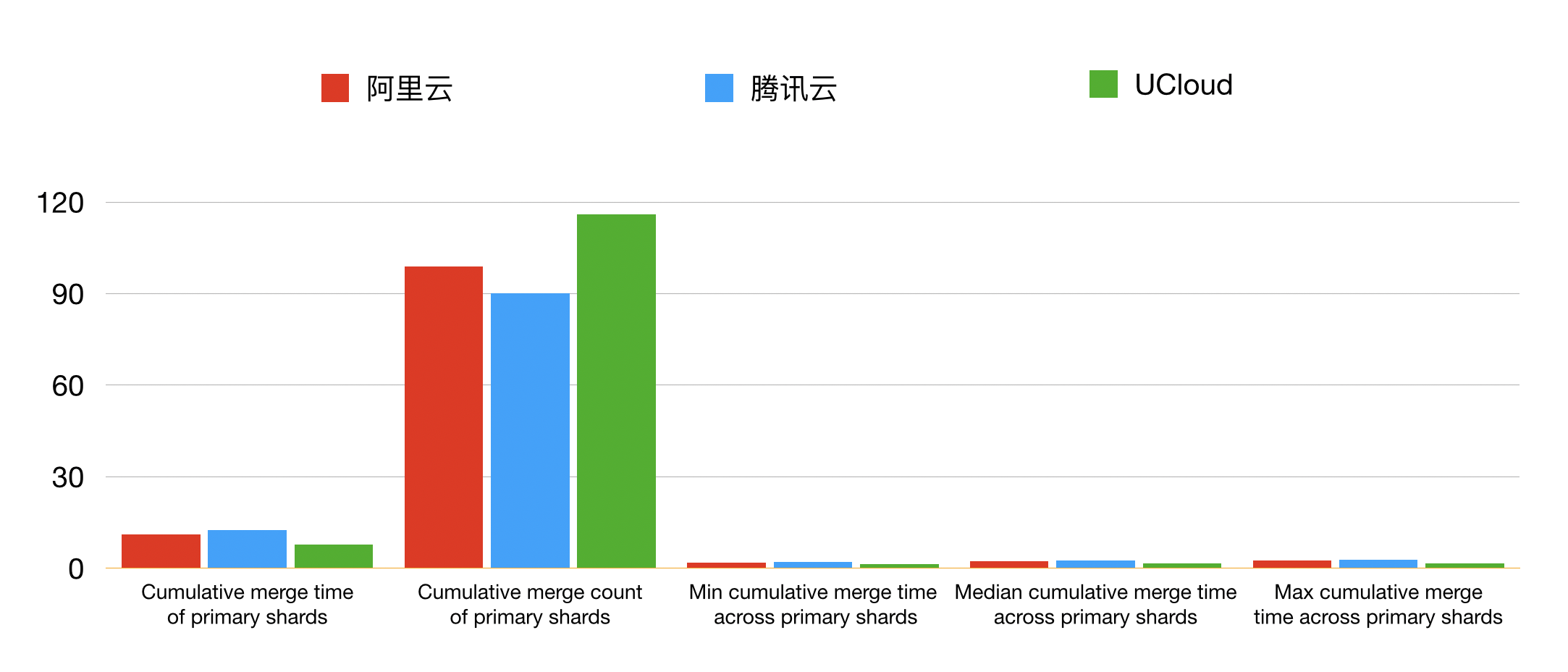
在本组测试结果中,腾讯云的计算时间耗费最长,阿里云可以在腾讯的基础之上,有约 9 % 的性能提升,UCloud 则在腾讯云的基础之上提升了 30%~40%
其他几组类似的数据,这里就不再一一介绍,大家可以自行下载文章最后的数据进行分析,评估,得出结论。
如何理解 Rally 返回的项目测试数据
除了宏观数据以外,Rally 返回数据中极大比例的是各种不同场景下的数据,这里,我们也选两组数据进行对比分析,看一看这些数据应该如何理解。
首先,我们看一下 node-stats 组的结果。
node-stats 组的结果是针对 node-stats 命令的数据分析结果。这里的吞吐量越大越好,时延则越小越好。
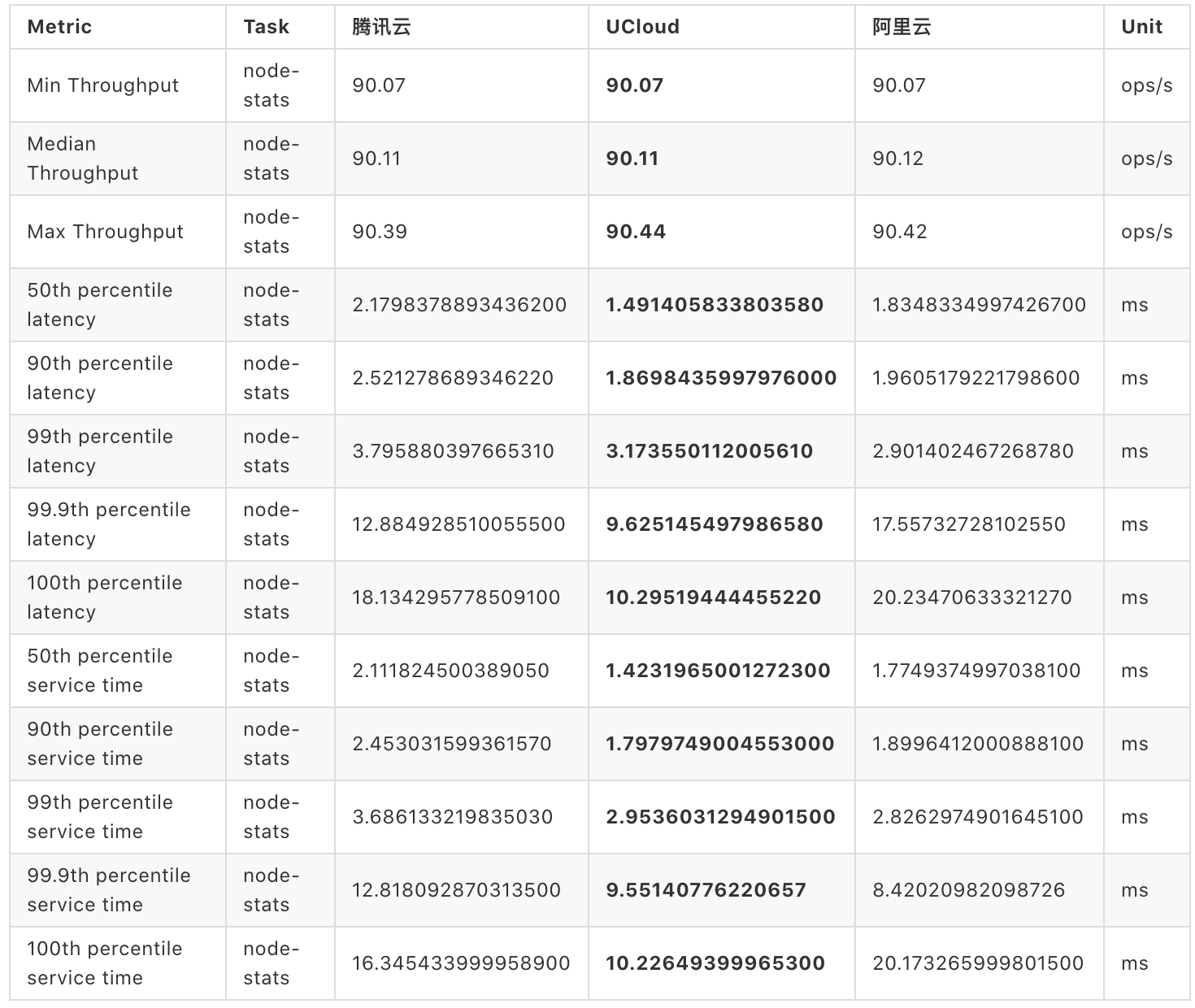
在本组测试结果中,阿里云、腾讯云、UCloud 在性能方面没有较大的差距。
类似的,我们可以对比 countryagguncached 组的结果
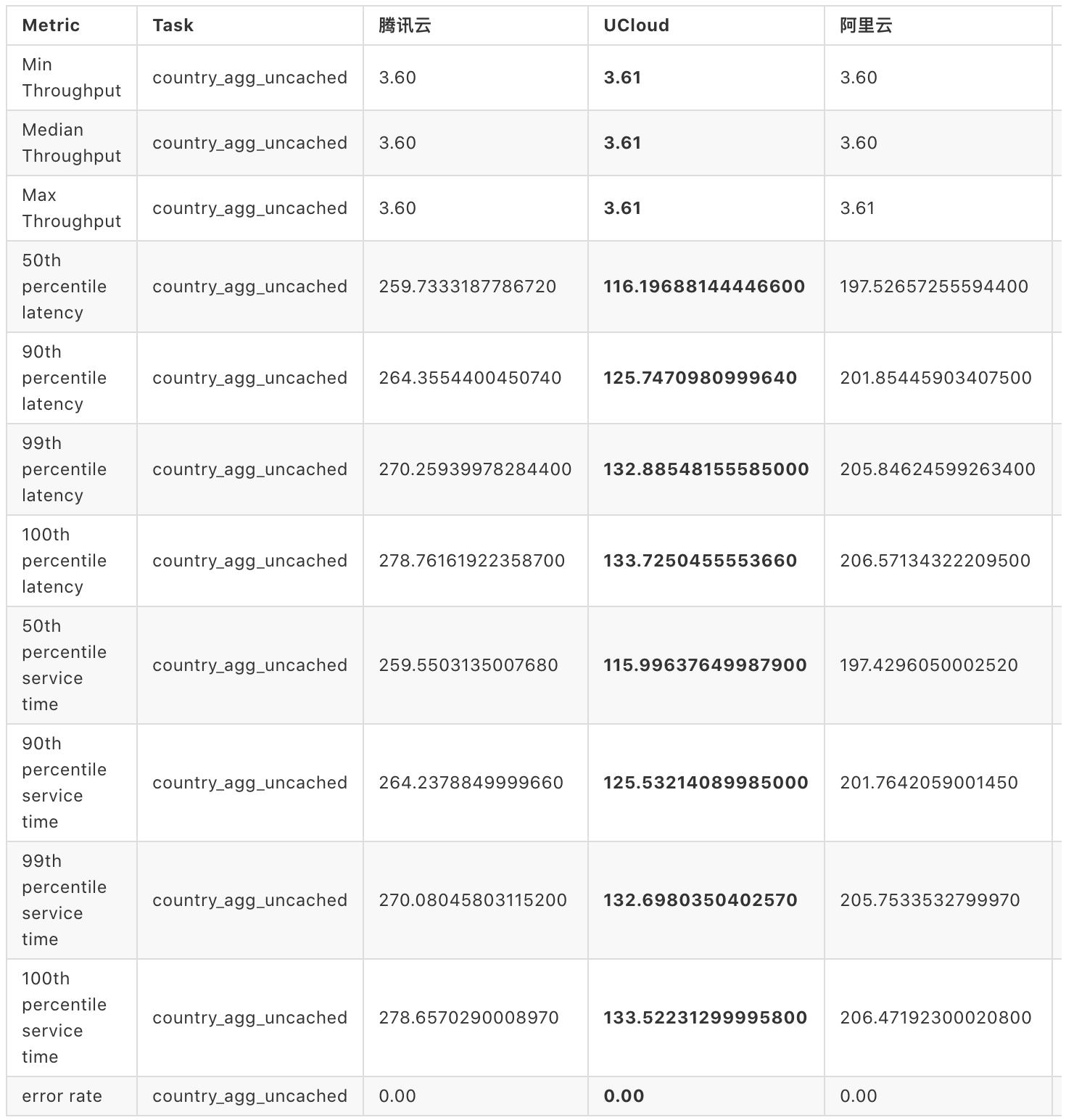
在本组测试结果中,阿里云、腾讯云、UCloud 在吞吐量方面没有较大的差距,时延方面 UCloud 会更好一点。
关于更多的数据,我们不在这里一一介绍,我将测试数据已经附在了文章的最后,你可以通过下载数据,自行分析,来练习 Rally 的使用和数据分析。
一些使用 Rally 时的小技巧
如何解决 Rally 网络不好的问题?
Rally 在执行时,需要下载相应的数据进行真实场景下的模拟,在这种情况下,Rally 需要从 AWS S3 上下载一些数据包,用于本地的测试。但国内的设备对于 S3 的访问不算太友好,经常会在下载的时候出现问题,因此,你可以选择前置下载数据,这样在测试的时候可以直接使用本地的数据来完成测试,减少失败的可能。
想要前置下载数据也很简单只需要执行如下命令:
curl -O https://raw.githubusercontent.com/elastic/rally-tracks/master/download.shchmod u+x download.sh./download.sh geonamescd ~tar -xf rally-track-data-geonames.tar
在执行 download.sh 时加入 track 名,就可以下载对应 track 数据的压缩包到本地,你可以根据自己的实际使用情况,来决定使用什么样的 track 模拟真实场景。
总结
在业务真正使用 ElasticSearch 之前,你可以像我一样,借助于 Rally 对备选的 ElasticSearch 集群进行压力测试,并通过对压测结果进行分析,从而获得明确的选型建议。比如,在我这次测试中,显然 UCloud 优于其他两家,是一个性价比 更高的选择。当然,这是一个实验环境下的压测,还是需要根据具体的业务场景做测试来进行选型,更为科学,不过希望压测方法能给予大家参考,也欢迎大家在后续实际的测试过程中给予我反馈。
附录
本文涉及到的测试数据均可以在下载地址找到。