Kubernetes 网络通讯模型解析
閱讀本文約花費: 7 (分鐘)
Kubernetes 基础架构
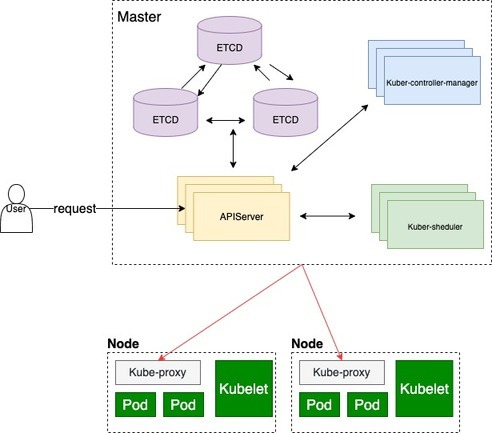 架构图
架构图
从架构图看到,一次外部访问请求,并不会直接请求到kubernetes中具体的某个集群或者某一个资源模块,是需要经过各模块资源间的调度来完成的。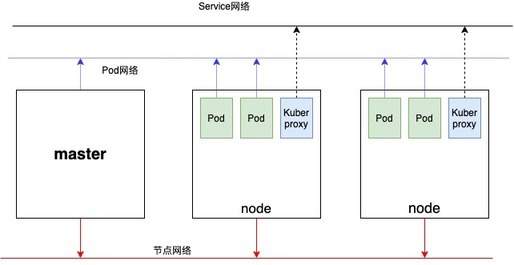 网络
网络
继续剖析Kubernetes的网络,如上图我们可以发现Kubernetes存在3种网络:节点网络,Pod网络,Service网络,最后再加上Internet与Service之间的网络总共4种。
于是我们可以总结Kubernetes需要解决4种通信模式:
1.容器和容器之间的通信
2.Pod和Pod之间的通信
3.Pod和Service之间的通信
4.Internet和Service之间的通信
容器和容器之间的网络
每一个Pod管理着一个或多个container,而对于同一个Pod之间的容器之间共享一个网络命名空间,它们之间可以直接通过localhost进行访问通信,这里以docker作为容器为例,容器间正好采用了container模式,额外创建启动一个容器,而这个容器不会有自己的网卡以及配置IP地址,而是和一个指定的容器共享IP和端口;
在Kubernetes里面每一个Pod都有这样的容器,叫做Pause,它有独立的命名空间,Pod会把新创建的docker通过—net=container的方式加入到Pause的网络命名空间,但是这里需要注意的是文件系统和进程列表等还是隔离的。
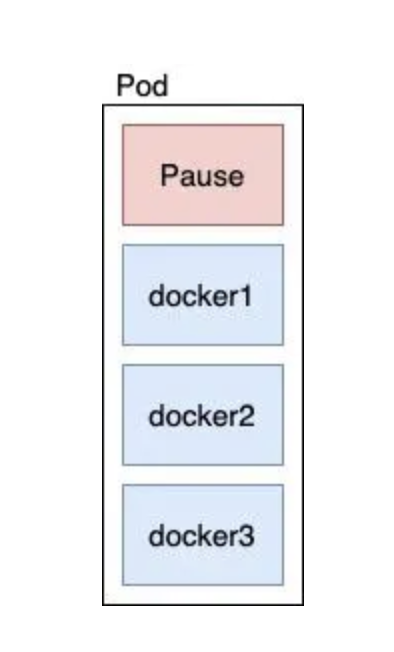
Pod和Pod之间通信
同一个Node之间的Pod
针对同一个Node下的Pod之间通信采用了Linux的虚拟网以太设备(以太网桥),即通过虚拟网以太设备将两个Pod的网络命名空间联系起来。大致流程是每一个Node都有一个root命名空间,每一个Pod通信时候都会通过以太网设备链接到root nets,然后root-nets再通过以太网设备转发到目的Pod的命名空间;
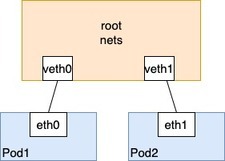
非同一个Node的Pod与Pod之间通信方式
基于同一个Node间的Pod的通信我们不难联想到在不同的Node之间可以再借助一个类似网桥的设备存储Node之间的Mac地址,如以下架构:
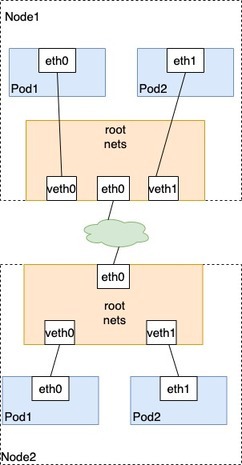
具体流程如下:
Node1中的Pod1通过以太网设备eth0把数据包发送到关联到root命名空间的veth0上,然后数据包Node1接受到数据包后,查找当前路由找不到Node2的Pod1的Mac地址,则把数据包转发中间网络,当数据包达Node2上后被Node2的eth0设备进行处理,Node2的root nets把数据流到veth0里,最后被流传到Node2的Pod1。这一就完成了一次Node之间的Pod通信;
具体通信实现
但是针对如果进行上述的网络配置,kubernetes本身没有具体实现,而是通过开发CNI接口供开源社区实现。由于目前CoreOS的Flannel在kubernetes实现CNI,这里针对Flannel的展开说明:
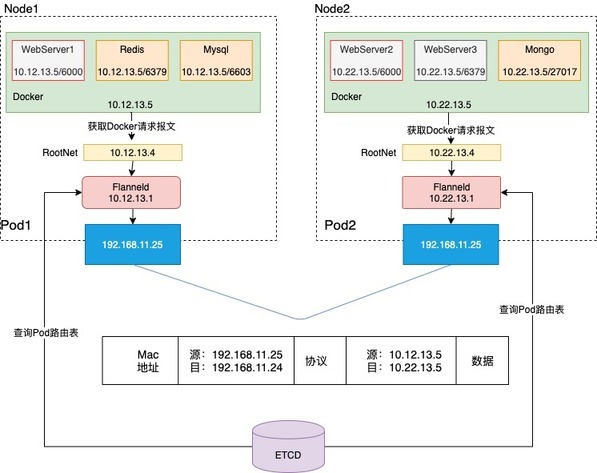
如上图:Node1中Pod1里WebServer1—>Node2中Pod2里的WebServer2
Node1-Pod1-WebServer1 (10.12.13.5)发现请求不在同一个Ip地址,则通过访问docker的统一eth0(10.12.13.5)将请求太网桥访问到Root-net
1.Root-net在本地中路由表中找不到于是把请求数据包分装给了flannel;
2.Flannel获取到数据包后通过查询ETCD得到Web1请求的数据包的Mac地址和目的Ip地址;
3.Flannel再次封装数据包传给Node1,并告知Node1目的Mac地址;
4.Node1通过Mac地址RARP找到了Node2,并把数据包给Node2;
5.Node2获取数据包或解析拆包 得知flannel的地址,这个时候Flannel再拆包,并发给Pod2的root-net;
6.Pod2的root-net通过以太网设备找到路由地址docker,然后把请求转发给docker;
7.最终docker获取请求后,解析数据包得到请求的webServer2地址是10.22.13.5;
这一就完成了一次非Node之前的网络通信请求
Pod与Service之间的通信
由于Pod销毁或者新增等操作,导致Ip地址不是持久不变的。这个时候就需要kube-proxy-service来实现Pod对外访问接口。
kube-proxy-service在逻辑上代表了后端多个Pod,在每一个Node中都会运行一个kube-proxy,集群Service都会通过kube-proxy-service 来访问到每一个Pod,而kube-proxy-service通过两种方式负载均衡:IPVS和Iptables;
IPVS:
基于LVS的4层负载均衡也许大家都不陌生,而LVS的IP负载均衡正是通过IPVS内核模块实现的,而IPVS的大致作用:安装在Director Server上,同时在Director Server 虚拟出一个IP地址,用户必须使用这个虚拟的IP地址访问集群服务。而在IPV中负载均衡依赖-netfilter框架。
IP Tables :
区别于IPVS的IP tables是用户态的应用,基于表来管理规则,在其内可以定义NAT,Filter,Mangle等规则参数。在Kubernetes中,kube-proxy的控制器来负责维护Ip tables ,该控制器的职责是监听Ip tables的变化,并实时通知到API-service,保证数据通过Service能准确传达到对应的Pod
Service和Internet之间的通信
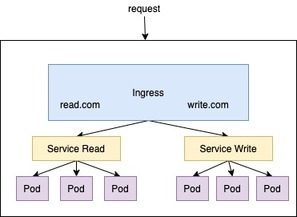
由于Ingress在绝大部分都用于Kubernetes在7层的接口对外暴露调用,这里可以使得Ks的Service无需通过IP:Port的方法是提供访问。至于为什么不使用Nginx,因为在Kubernetes中Service变化十分频繁,人为的手动修改变得不太可能,因此ingress被运用到kubernetes中实现service与Internet之间的通信。以下Ingress进行展开简单的举例说明;
ingress相当于一个7层的负载均衡器,是对kubernetes反向代理的一个抽象。工作原理也确实类似于Nginx,可以理解成在 Ingress 里建立一个个映射规则 , ingress Controller 通过监听 Ingress这个api对象里的配置规则并转化成 Nginx 的配置(kubernetes声明式API和控制循环) , 然后对外部提供服务。基于具体的Ingress工作原理和配置这里不作更多复述。
本文参参考资料如下:
https://kubernetes.io/zh/docs/home/
https://kubernetes.io/zh/docs/concepts/services-networking/ingress/