CephFS+Kubernetes 在网易轻舟容器平台的实践
閱讀本文約花費: 8 (分鐘)
在网易集团,基于 Kubernetes 构建的网易轻舟云原软件生产力平台扮演着支撑数字化业务快速高效创新的重任,帮助业务团队快速实现云原生应用,提高研发效能,并节省运维成本。
作为网易轻舟云原生平台的存储后端,CephFS 主要为网易轻舟容器平台 NCS 解决容器间共享存储的问题。尤其是在当前比较火的 AI 训练场景应用十分广泛,存储规模达已达数 PB 级,CephFS 的性能优化等工作非常重要。
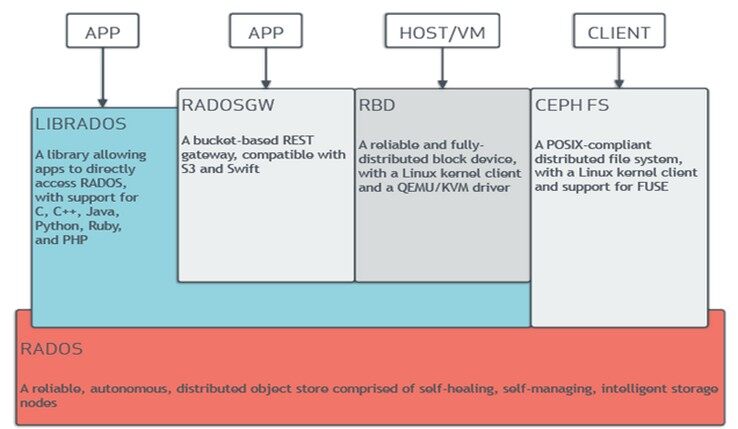
Ceph 和 CephFS 简介
Ceph 由 RADOS 作为底座,上层提供对象、块、文件等接口服务。RADOS 由 MON、OSD、MGR 组成,MON 负责集群的各类视图(osdmap,pgmap 等),健康状态的管理。MGR 则提供了丰富的系统信息查询功能,以及支持第三方模块接入(Zabbix,Prometheus,Dashboard 等)。OSD 则负责最终的数据存储,一般一个 OSD 对应一块磁盘。
CephFS 在此架构基础之上增加了 MDS 和 client,其中 MDS 负责文件系统的元数据管理和持久化操作。client 则对外提供了兼容 POSIX 语义的文件系统客户端,可通过 mount 命令进行挂载。
CephFS 典型实践
部署
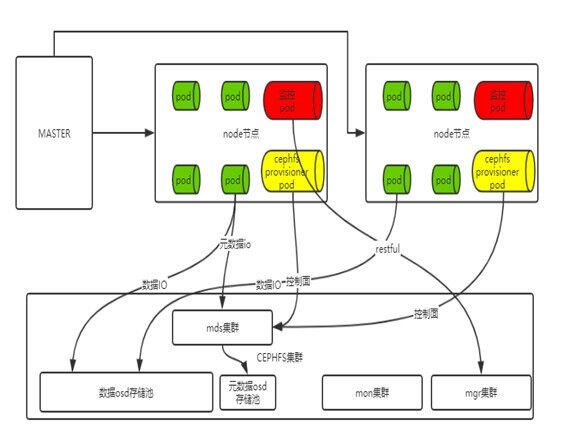
整个 CephFS 在轻舟 Kubernetes 环境中的部署架构如下:
在 Kubernetes 的使用场景里,CephFS 集群的部署和常规 Ceph 类似,为了提高元数据处理能力,一般会将元数据 pool 单独用 SSD 的 OSD 来搭建独立的物理池。Kubernetes 社区提供了 cephfs-provisioner 来支持分配 pv,以及进行 client 的挂载。通过将 ceph-client 挂载在 node 节点上,最终映射给 Pod 使用。同时会有对应的 Prometheus 监控 Pod 对集群进行各项指标的监控和告警。
CephFS pv 性能监控
在云原生的存储系统中,IO 的可观测性是一项重要指标,也是我们最终客户迫切需要的需求。原生的 CephFS 在客户端性能监控方面做得比较简单,网易杭研存储团队丰富了读写性能指标项,最终集成在网易轻舟平台上。用户可以直接的看到业务的性能可使用情况,具体如下:
CephFS 支持多性能类型 pvc
为了满足业务的不同存储性能需求,我们为 CephFS 提供了多性能后端的 pvc 类型。该方案需要 Kubernetes 和 CephFS 两方配合完成,我们以常见的 SAS,SSD 后端存储类型为例进行描述,具体如下:
1. 创建 CephFS 集群,包括 MON,OSD,MDS,MGR 服务等。
2. 在 crush 规则中创建物理池,即 meta_root,data_sas_root,data_ssd_root。其中 meta_root,data_ssd_root 由 SSD 盘对应的 OSD 组成,data_sas_root 由 SAS 盘对应的 OSD 组成。
3. 创建逻辑 pool,分别在上述的 3 种类型的 root 中创建 meta_pool,data_sas_pool,data_ssd_pool。

4. 创建文件系统,并指定 meta,data 逻辑 pool。复制代码
ceph fs new fs_name meta_pool data_sas_pool
5. 在 CephFS 的文件系统根目录下创建 2 个子目录,即 /pvc-volumes-sas 和 /pvc-volumes-ssd,目录所属用户和组为 root:root,权限 777
6. 为上述 2 个目录指定存储池。复制代码
setfattr ‐n ceph.dir.layout.pool ‐v data‐sas pvc‐volumes‐sas setfattr ‐n ceph.dir.layout.pool ‐v data‐ssd pvc‐volumes‐ssd
7.Kubernetes 可在这两个目录下创建对应类型的 pv 提供给 pod 使用。CephFS 会将写入不同目录的数据写入到指定的存储类型设备上 (SAS/SSD)。以下我们来举例说明:
1). 创建 StorageClass,并等待 ceph 开发配置好对应的存储池(上面的步骤 6)复制代码
kind: StorageClass metadata: name: cephfs‐provisioner‐sc‐sas ## 或者 cephfs‐provisioner‐sc‐ssd provisioner: ceph.com/cephfs volumeBindingMode: WaitForFirstConsumer parameters: monitors: 192.168.27.43:6789,192.168.27.44:6789,192.168.27.45:6789 adminId: admin adminSecretName: csi‐cephfs‐secret adminSecretNamespace: "kube‐csi" claimRoot: /pvc‐volumes‐sas ## or /pvc‐volumes‐ssd
2). 创建 pvc复制代码
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: claim‐sas ##claim‐sas spec: accessModes: ‐ ReadWriteOnce storageClassName: cephfs‐provisioner‐sc‐sas ##cephfs‐provisioner‐sc‐ssd resources: requests: storage: 30Gi
3). 使用 pvc复制代码
# pod 使用 pvc apiVersion: v1 kind: Pod metadata: name: task‐pv‐pod spec: volumes: ‐ name: task‐pv‐storage persistentVolumeClaim: claimName: claim‐sas ## pvc name containers: ‐ name: task‐pv‐container image: nginx ports: ‐ containerPort: 80 name: "http‐server" volumeMounts: ‐ mountPath: "/usr/share/nginx/html" name: task‐pv‐storage
复制代码
# deployment 使用 pvc apiVersion: apps/v1 kind: Deployment metadata: name: nginx‐with‐pvc spec: replicas: 1 template: metadata: labels: service: nginx app: test spec: containers: ‐ image: nginx name: nginx‐with‐pvc volumeMounts: ‐ mountPath: /test‐pvc name: my‐sas‐pvc volumes: ‐ name: my‐sas‐pvc persistentVolumeClaim: claimName: claim‐sas ## pvc name
CephFS 线上问题分析与优化
CephFS 产品在测试和上线后也遇到过不少问题,这里举几个例子分享一下。
ceph-fuse io 性能优化
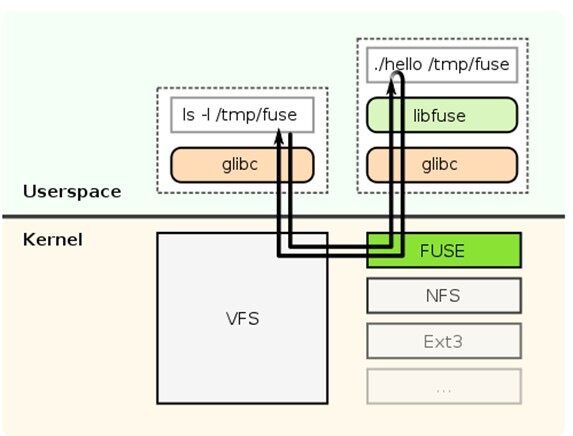
问题现象:
某用户在使用 dd 命令:dd if=/dev/zero of=./test2 bs=1M count=100 oflag=direct 写一个文件的时候 io 性能只能达到 30MB/s,而本地文件系统可以达到 100MB/s 的写入性 能,差距较大。
问题分析:
1. 我们调整了 dd 的 bs 参数设置到 2M,256K,128K,64K 分别进行了测试
2. 发现当 bs 小于 128k 的时候,带宽会变小,bs 大于或等于 128k 的时候带宽始终不变。
3. 如上图,我们分析 fuse 内核态代码 (fuse.ko) 以及 libfuse 都有对 IO 的限制,当 IO 大于 128k 的时候会进行拆分同步下发。
问题解决:
1. 修改了对应的 fuse 限制相关的代码,加载新的 fuse.ko 以及 libfuse。
2. 重新测试 dd 命令,在 bs=1M 的时候性能从 30MB/s 提升到 120MB/s。
CephFS 空间回收优化
问题现象:
某用户反馈在 PV 中实际数据只有几百 G,但是通过监控显示实际占用 10 多 T 的空间,使用率已经达到 70% 以上,如下图。
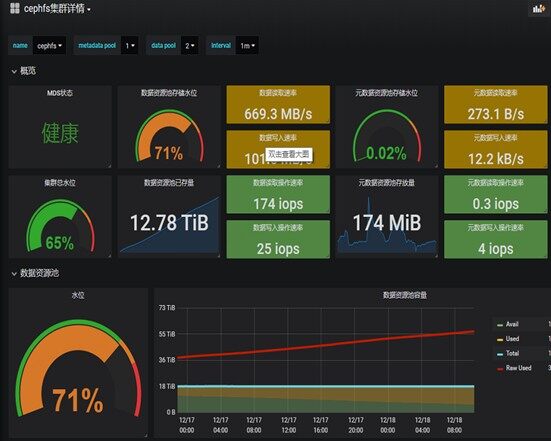
问题分析:
1. 通过和用户沟通,了解到大致的应用场景是持续不断的写文件以及删除老文件。
2. 而我们通过水位的监控看到容量一直在持续增长。
3. 通过 Ceph 的工具查看到回收站中待删除文件达到 3 万多,但是并无文件被删除,如下图。
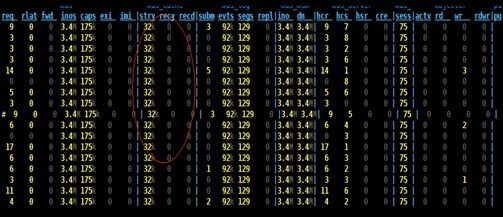
4. 通过 Ceph 的命令工具发现有几十个 client 连接着 ceph-mds。个别 client 拥有几万的 caps(文件句柄)。由此可知文件虽然被某个 client 删除,但是其他的 client 还未将文件关闭,导致文件一直处于待删除状态。
问题解决:
1. 推动用户将有问题的 client 文件句柄进行释放,则触发文件删除,最后集群容量降下来了。
未来的工作
多 MDS 负载均衡
当前 CephFS 使用的还是主备 MDS,我们已经发现单 MDS 间歇性会因为瞬时的处理请求太多而产生 slow request。接下来我们会切换到多活 MDS,对用户不同的 pv 到 MDS 的映射进行统一调度,避免单一 MDS 的负载过高,有效提升整个存储系统的性能。
性能优化
读写时延的降低以及并发能力的提高在典型应用场景 AI 训练上,能够大幅度降低训练周期,使多个业务方受益。接下来我们会在 SSD Cache,以及当前的 IO 瓶颈分析方面持续优化改进,增强网易存储产品竞争力。
作者简介:
胡遥,网易杭州研究院 Ceph 存储负责人。